[Dolmetscher wissen alles] Interpreters know everything
A blog on knowledge & conference interpreting
-
Distance interpreting – AIIC’s guidelines in practice | a guest article by Mathilde Kuhn
As I was looking for a subject for my master’s thesis, I read in many articles and books that remote simultaneous interpreting (RSI) is not very popular amongst interpreters. It comes with multiple difficulties: communication with a boothmate is harder, internet connections can be unstable, lack of social contact, health risks, etc. To mitigate the…
-
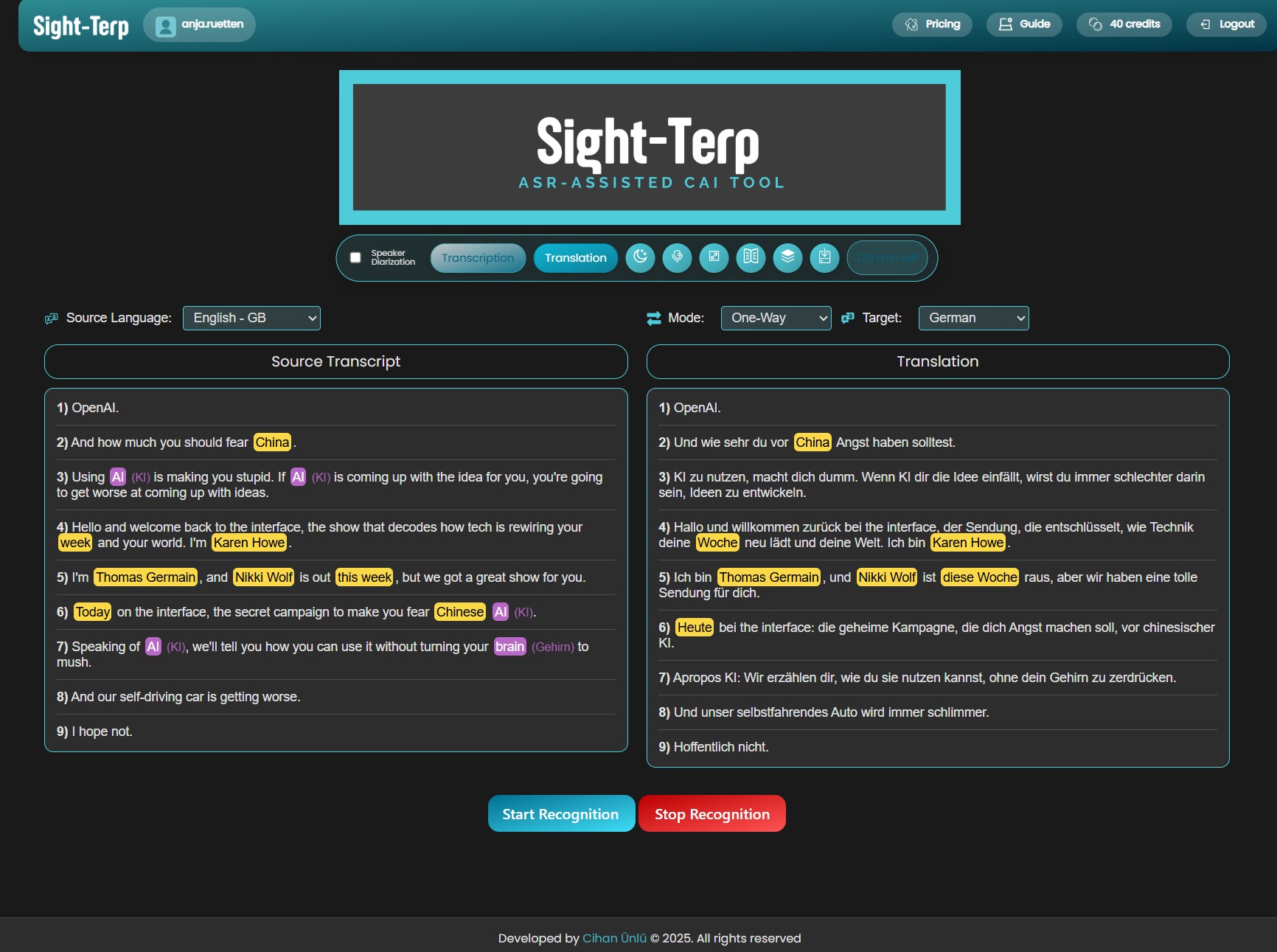
Sight-Terp – a live-prompting boothmate including interpreter training support
by Viviana Tipiani Yarlequé and Anja Rütten The latest Computer-Aided Interpreting tool that has made its way to the CAI market is Sight-Terp. It has been around since November 2025, which was exactly the time when we had our three-day intensive CAI testing weekend in Cologne. Whilst we could only accomodate a short test cycle…
-
Fast but awkward vs. well thought-out but slow – Comparing machine translation to human translation | guest article by Luca Etzold
AI and with it MT has been gaining more and more traction in the language industry. However, human translators have not gone extinct just yet, and there are good reasons for it, some of which I explored as part of my Master’s thesis. In it, I translated a podcast interview from English to German and…
-
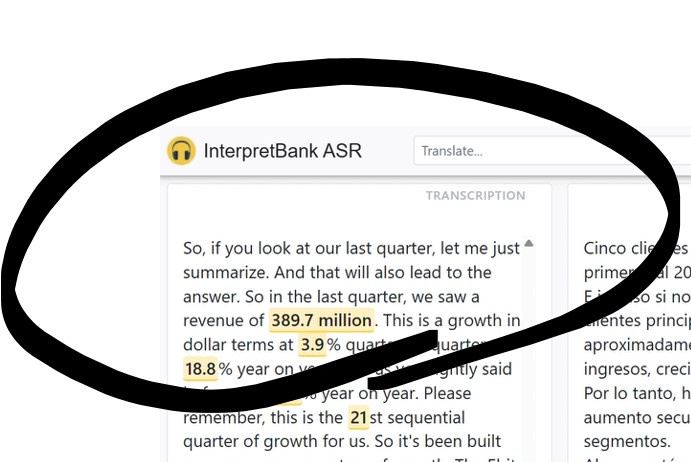
InterpretBank ASR going offline
by Magda Lindner-Juhnke and Anja Rütten InterpretBank by Claudio Fantinouli has been around since the 2000s and has already been the topic of three posts on this blog (The Artificial Boothmate in Action, New Term Extraction Features in InterpretBank and InterpretersHelp, InterpretBank 4 review). When it was launched, it was one of the pioneers of…
-

Professional ethics – do they need future-proofing? On the art of telling things apart
Intro Discussions about professional ethics in conference interpreting have lately struck me as rather unsatisfactory. Can we impose our European fees on colleagues from different continents when working remotely? Can I do two assignments in one day? Can I just switch on my Computer-Aided Interpreting tools in the booth and have AI listen to the…
-

Xmas wings
Wüchsen mir Flügel, Über die Hügel Wollt ich mich schwingen zum Himmel empor, Frei wie der Vogel die Wipfel ersteigen Und aus den grünen dämmernden Zweigen Lustige Lieder schmettern im Chor. […] Julius Wolff *** Mes vers fuiraient, doux et frêles, Vers votre jardin si beau, Si mes vers avaient des ailes, Des ailes comme…
-

Cologne CAI Testing
click for booth tour video Last November, finally, we received our first group of CAI-crazy guests at Cologne’s CAI Campus. A fabulous team of eight AIIC Science Hub members met to spend three very intensive days at TH Köln to work with different CAI tools. It was the CAI Campus inaugurational pilot run, a tool…
-
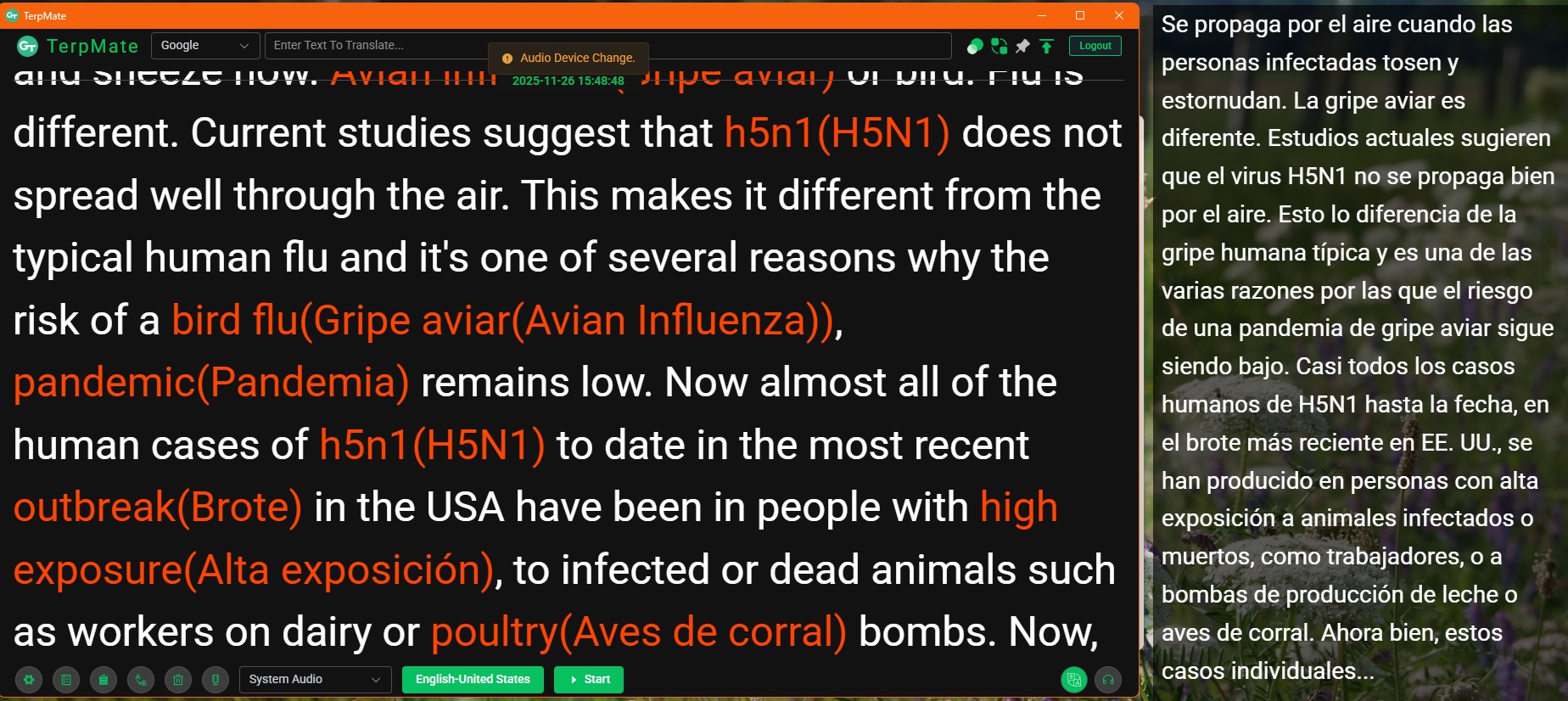
TerpMate – the (second) newest kid on the block of CAI tools
TerpMate was published in April this year (2025). It was the latest addition to the CAI tool landscape indeed, just until SightTerp was released last month (review coming soon). Now, TerpMate is part of the Greenterp ecosystem created by Green Terp Technologies Pte Ltd and their CEO Bernhard Song, who himself is a professional conference…
-

Bilingual songs, cloze texts, emotional EU debates, texts with numbers – some creative chatbot prompts for conference interpreting practice
This year, both myself and my students at MAKD were quite inspired when it came to using AI to generate creative interpreting exercises. So I thought I might share some examples for other interpreting students, teachers, and professionals to use. And of course, feel free to share other examples of AI-supported exercises for student interpreters…
-

Privacy, sensitive data, intellectual property – what’s there to protect in times of AI
No matter if we use AI to support or even replace translators, interpreters, or any other profession, there is always that “legal” question lingering in my – and seemingly everybody’s – mind: Is “the AI” being trained on my voice, my translation, my ideas? Will sensitive information end up in this black box LLM and…
-

Finding a prompt to prepare an interpreting text in under 5 minutes with the help of AI-based chatbots | guest article by Lea Kortenbusch
Call me lazy for letting my students do all the blogging lately … but they just come up with such great stuff! So here’s Lea telling us how she discussed the definition of “technical term” with an AI and had five chatbots extract terminology and other useful information for her. Guest article by Lea Kortenbusch,…
-

AI-made podcasts by NotebookLM and Jellypod
AI generated podcasts – are they any good for meeting preparation, or for conference interpreter training? My student Rebecca Bremer, a real podcast aficionado, wanted to find out and did some testing. Here’s what she has found out: Guest article by Rebecca Bremer, student of conference interpreting at TH Köln General considerations Podcasts have become…
-

Interpreting Europe – navigating the AI landscape without leaving anyone to their own devices
One minute summary Say “I don’t know” and “it depends” with confidence (Get to) know possible use cases of Automatic Speech Translation (make students) understand AI Let’s do meaningful empirical research Barely a month and a half into the new year, a lot has already been said about AI in conference interpreting, after last week’s…
-

Lara Translate – offering faithful, fluid, or creative machine translation
When a spoken text is being interpreted, the target text is often less attached to the morpho-syntactical structures of the source text than that of a written translation. Complex sentences are disentangled, so that they are easier to process and represent less of a cognitive load both to interpreters and to listeners, redundancies are smoothed…
-

✨ Wishing you many a secret helper in life ✨
✨ Wishing you lovely holidays – and many a secret helper in life! ✨ ✨ Je vous souhaite de joyeuses fêtes et qu’il y ait toujours une myriade de petits assistants à vos côtés. ✨ ✨ Deseándoles felices fiestas, y ¡que siempre tengan un asistente secreto a su lado! ✨ ✨Wunderschöne Feiertage und immer ein…
-

BYOD – Bring your own display (to the booth and elsewhere)
I think being completely paperless (except for Christmas cards) is just fab for a great number of reasons. However, there are two aspects of working with just a tiny laptop that I have never quite come to terms with: 1. The space available on a small laptop screen is rather limited. Maybe this is just…
-

Chatting about AI with Olivier Péan, OECD chief interpreter | AIIC AI podcast
At the AI workstream of AIIC’s Science Hub, we had the pleasure recently to chat with Olivier Péan, chief interpreter at the OECD, about all things AI in conference interpreting. I hope you enjoy the chat as much as I did! Looking forward to reading your comments on the AI Workstream’s LinkedIn channel!
-

Getting to know Boothie, the University of Gent’s CAI project
The Ergonomics for the Artificial Booth Mate (EABM) project conducted at the University of Ghent has been catching my attention for a while, with all these experiments on cognitive load in the booth run by Bart Defrancq. The CAI tool associated with the project, Boothie, provides live-prompting of terms and numbers in the booth along…
-

Testing Cymo Note
Testing software in a group of tech-crazy interpreters is so much more entertaining and insightful than just playing around on my own. AIIC’s AI workstream (link to LinkedIn profile) recently embarked on its first team testing session, and we chose Cymo Note as our first subject of interest. Cymo offers a whole range of support…
-

Live prompting CAI tools – a market snapshot
In the aftermath of our inspiring AIIC AI Day in Rome, I felt that an overview of all live-prompting CAI (Computer-Assisted Interpreting) tools might be very much appreciated by many colleagues. So here we go – these are the tools providing live prompting of terms, numbers, names or complete transcripts in the booth during simultaneous…
-

Here’s Truedic, my Mistral.ai-based (formerly ChatGPT-based) booth assistant for fast & easy vocab searching
OpenAI’s GPT builder is by far the greatest toy since the invention of pinball. After Truedee, my meeting preparation assistant, I have now created Truedic, a booth assistant that helps me check unknown words or expressions while interpreting in all my working languages. Here’s how it works: At the beginning of each session, it will…
-

Being interpreted by AI – a speaker’s and listener’s perspective
A real first: Last week for the first time ever I spoke at an international event in German, my mother tongue. And on top of that, I was being interpreted by both a machine (in subtitles) and humans. I had the honour to be a member (the only remote one) of an illustrious panel invited…
-

Eight rules to get the most out of live translation apps
This month at the Technical University of Cologne we took a closer look at some live translation apps, in particular Galaxy’s live translation app for phone calls. Prof. Ralph Krüger and I, together with journalist Steffen Berner, wanted to find out how useful they are. It was both an interesting and entertaining experience. Obviously, nothing…
-

Recap of VKD’s round table discussion on artificial intelligence
As promised, here comes the English version of my article published in the German conference interpreters’ association (VKD im BDÜ e.V.) bulletin “VKD-Kurier“ in December 2023 Quo Vadis yet again? On 17 October 2023, VKD hosted a virtual round table discussion on AI. I was invited to give a keynote speech – a dubious honour…
-

Meet Truedee, my Mistral.ai-based (formerly ChatGPT-based) preparation assistant
So ChatGPT now lets you create your own custom ChatGPT using OpenAI’s no-code platform GPT builder … about time, I thought, to give it a try and create my own chatty conference preparation assistant, TrueDee. We are not exactly soulmates yet, as TrueDee tends to be a bit erratic, ignore my wishes, and hallucinate. But…
-

Season’s greetings from paradise * Paradiesische Feiertage * Unas fiestas paradisíacas * Des fêtes paradisiaques
(if you can’t open the short video, click here) Die ersten Weihnachtsbäume wurden schon im 15. Jahrhundert mit Früchten und Nüssen geschmückt. Unter anderem wurden Äpfel an den Baum gehängt, die an die verbotene Frucht des Baumes der Erkenntnis erinnerten. Nicht umsonst haben Adam und Eva am 24. Dezember Namenstag. So steht der Apfel für…
-
Nachlese zum Runden Tisch des VKD im BDÜ zum Thema Künstliche Intelligenz
Artikel aus dem VKD-Kurier Dezember 2023 [English version here] Quo vadis denn jetzt schon wieder? Am 17. Oktober 2023 lud der VKD zum virtuellen Runden Tisch in Sachen KI ein. Mir wurde die Ehre zuteil, ein Impulsreferat halten zu dürfen – für meine Begriffe eine zweifelhafte Ehre, weil in meinem Kopf über allen Fragen rund…
-
Live transcription in RSI with Otter.ai and Airgram.io
Yesterday, in a Remote Simultaneous Interpreting team with colleagues being distributed all over Europe, it suddenly occurred to us to play around a bit with live transcription as a support (thanks to Mike Morandin’s innocent question if anyone had ever used it). No sooner said than done – within a few minutes our wonderful chef…
-

The InterpretBank Artificial Boothmate in action | guest article by Benjamin Gross
As interpreters, we’re used to being team players. We don’t like to work alone – whether that be in a booth on-site or remotely from our home offices. Whatever we do, we can trust our favourite people – our booth mates. So what if we could have an additional mate in our booth? A mate…
-
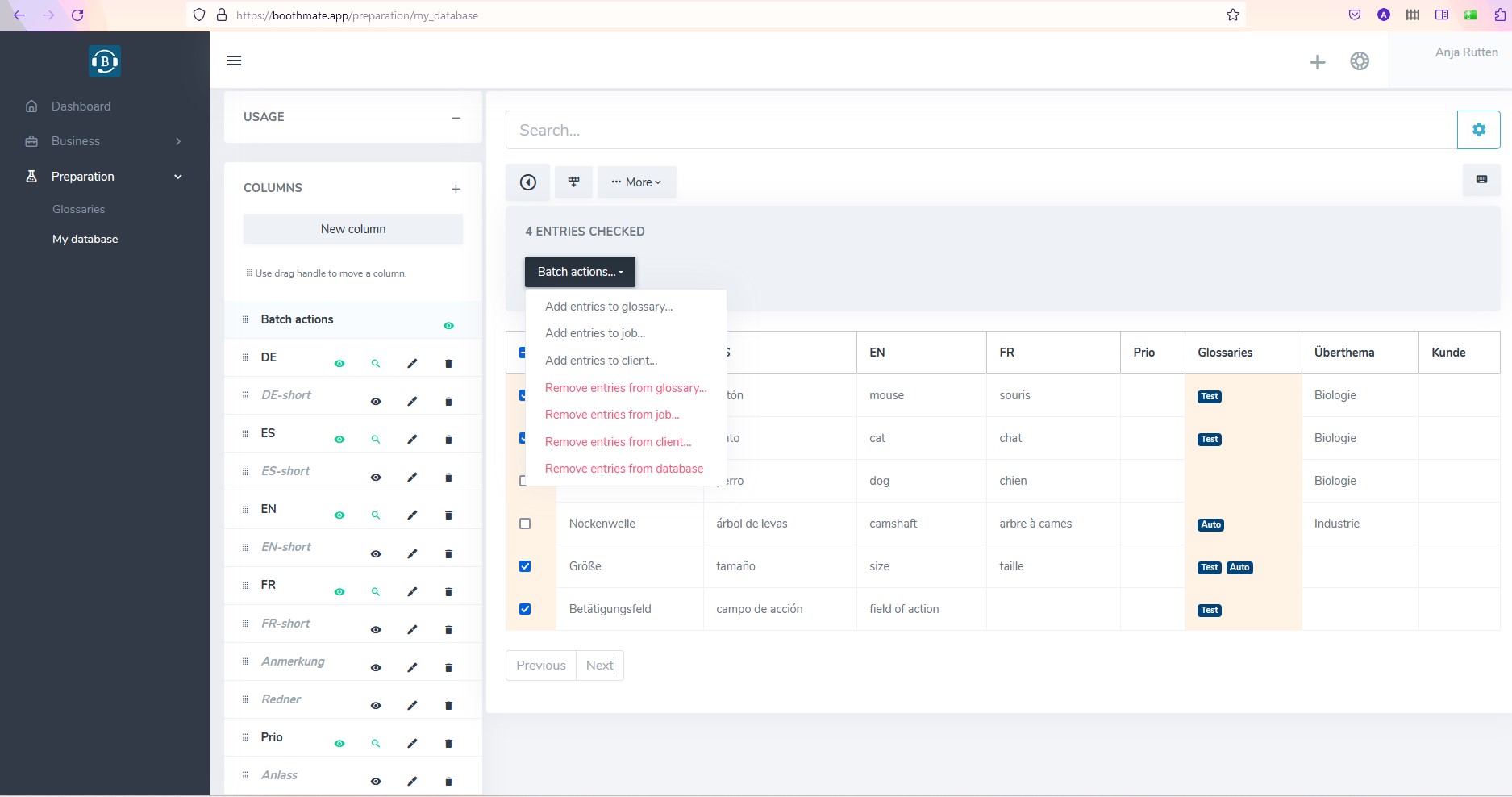
New (beta) version of Interpretershelp with lots of great new features to discover ️- now available at boothmate.app
InterpretersHelp is a very straightforward browser-based terminology and job management application that allows for secure online collaboration. It is great for keeping your terminology up to date on all devices and sharing it with colleagues. It has been around for about ten years now, reason enough for Benoit Werner, co-founder and technical brain of this…
-

Chatting with Lourdes de Rioja about AI, professional domiciles, economic literacy, blogging, and the relevance of information
Being asked the right questions by the right person can be so inspiring … thank you very much to the great Lourdes de Rioja for chatting with me about AI, professional domiciles, economic literacy, blogging, and the relevance of information. *** Fue un placer enorme ser entrevistada por la gran Lourdes de Rioja. ¡Cuán inspirador puede…
-

What’s conference interpreting after all?
How to define “conference interpreting” We will be celebrating AIIC’s 70th anniversary in July. Earlier this year, we celebrated the German VKD’s 20th anniversary in Berlin, where I handed over the responsibility of chairing the VKD admissions committee. Both occasions as well as many inspiring conversations I have had recently left me musing about a…
-
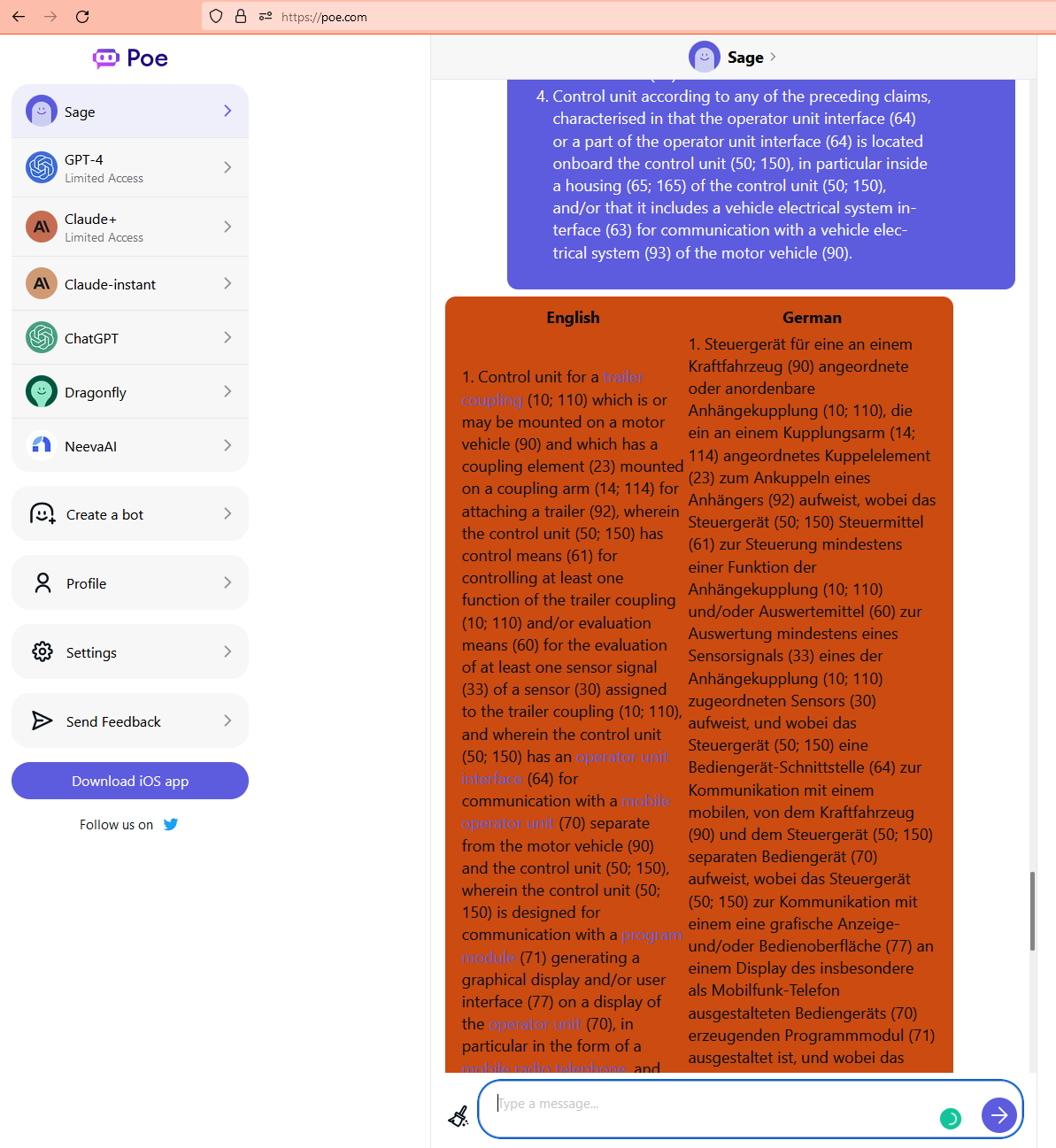
How to tell a chatbot like ChatGPT or Sage to align texts in different languages in a table (and besides get a summary )
If you have the same text in several languages and you want the different versions neatly arranged in a table with the sentences in the different language versions next to each other, a chatbot like ChatGPT may be able to help. Especially when texts come in pdf format, just copying and pasting them can already…
-
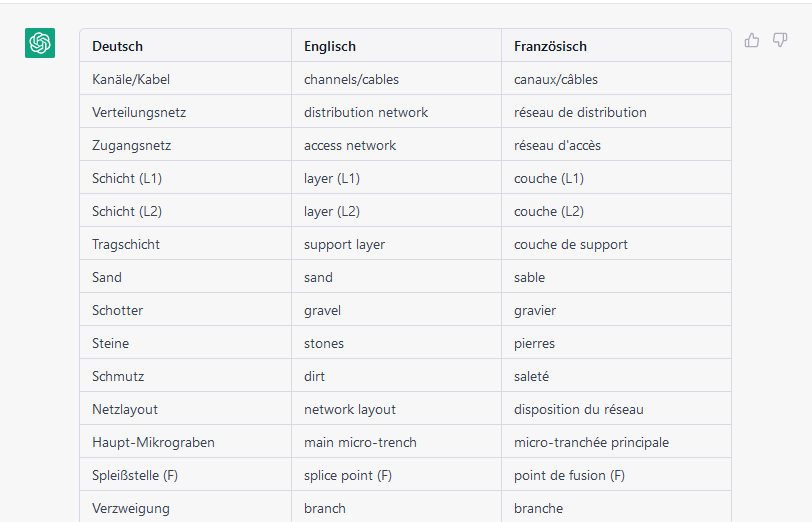
How to tell ChatGPT to extract terminology from parallel texts in different languages
My dear colleague (and former student) Florian Pfaffelhuber just drew my attention to the fact that ChatGPT is great at multilingual terminology extraction. It can also handle more than two languages and will create very nice multilingual glossary tables for you. What worked best when we tested it today was to copy the prompt and…
-

Use ChatGPT, DeepL & Co. to boost your conference preparation
In this article I would like to show you how I like to use DeepL, Google Translate, Microsoft Translator, and ChatGPT as a conference interpreter, especially in conference preparation. You will also see how to use GT4T to combine the different options. I did some testing for this year’s Innovation in Interpreting Summit and I…
-

Cognitive sustainability for conference interpreters (and other high intensity knowledge workers)
Cognitive sustainability Flight-shaming, banning fast fashion, upcycling old milk cartons, taking financial precautions for when we are old or a pandemic strikes – it’s sustainability all around. But what about our most precious working resource – our brain? Is “cognitive sustainability” a thing at all? Sustainability There are many definitions of sustainability. Although originally coined…
-

Kognitive Nachhaltigkeit bei der Wissensarbeit
Kognitive Nachhaltigkeit Es begab sich in diesem Januar 2023 vor dem Dolmetscher-für-Dolmetscher-Workshop (#dfd2023, organisiert durch das fabelhafte Fortbildungsteam von @aiic_de), der sich dem übergroßen Thema der Nachhaltigkeit verschrieben hatte, dass ich mir Gedanken machte zu der Frage, wie kognitiv nachhaltig wir eigentlich sind. Wie es sich gehört, stand am Anfang die Frage: Was ist das…
-
Everyone deserves a bit of tinsel ✨ Jeder verdient ein bisschen Lametta ✨ Todos nos merecemos un poco de oropel
2022 war für mich das Jahr der wundervollen Begegnungen. Mögen alle, die sich hiervon angesprochen fühlen, und auch alle anderen sich mit Glanz und Gloria gefeiert fühlen! 2022 was my year of wonderful encounters. So here’s to all those I shared real or virtual moments with, and to everyone else! May you all feel celebrated…
-
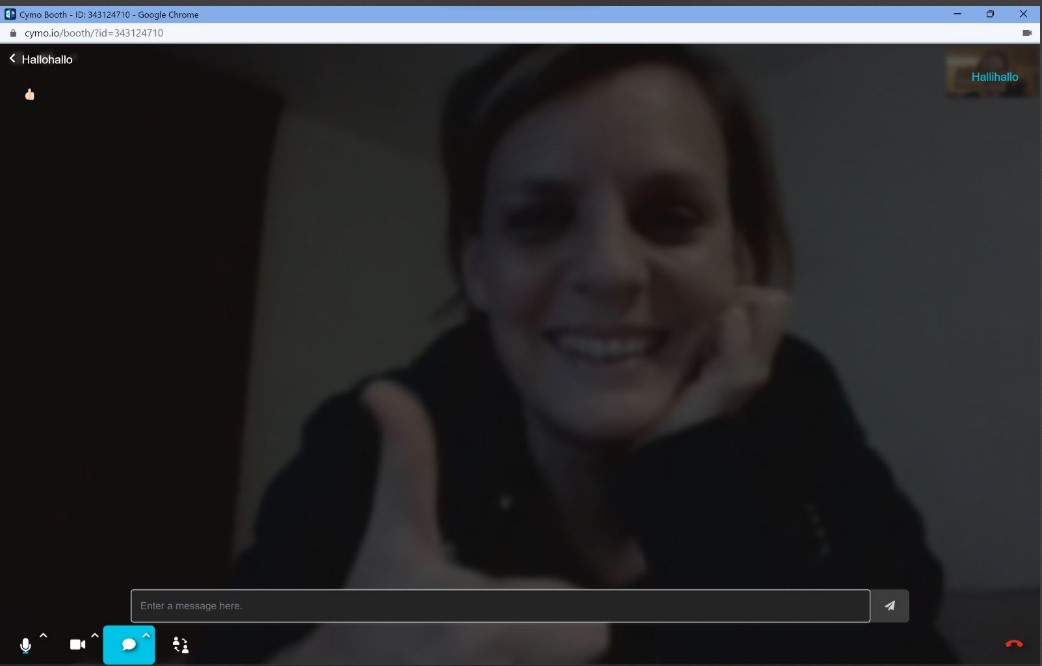
Cymo booth – great, easy-to-use private booth channel for interpreters on Zoom
When Peter Sand mentioned Cymo Booth recently as a solution to having a private video/audio/chat channel with your remote boothmate while interpreting on Zoom, my spontaneous reaction was “Oh no, not another video channel on my already over-crowded screen …” But luckily, Angelika Eberhardt talked me into trying it nonetheless. Or rather, she simply sent…
-

Automatic bilingual term extraction with OneClickTerms by SketchEngine
When I wrote about this great terminology extraction tool OneClickTerms back in 2017 I was already quite enthusiastic about how useful it was for last-minute conference preparation. But the one thing I didn’t mention back then (or maybe it wasn’t available yet) was that OneClickTerms does not only extract terminology from monolingual documents, but it…