[Dolmetscher wissen alles] Interpreters know everything
A blog on knowledge & conference interpreting
-

The new IATE interpreters’ view – what’s in it for EU meeting preparation?
The EU’s terminology database has been around for quite some time – the project was launched back in 1999 and has been available to the public since 2007. Recently, it has been revamped, and an “interpreters’ view” has been added. All EU interpreters, staff and freelancers alike, have access to it, and it is tailored…
-

Some thoughts on the importance of trust in conference interpreting | by Karin Walker and Anja Rütten
The first time I (Anja) worked with somebody I only knew virtually, without any personal connections or references, was back in 2001, still in times of the Deutsche Mark: I worked on a Spanish translation project together with a complete stranger, a colleague I made contact with via an electronic mail list for translators. We…
-

Meine erste Workation – über Vertrauen im Dolmetschberuf und Pausen in Pink
Als ich mich vor einem Monat auf nach Rhodos zur ersten Workation meines Lebens machte, waren meine Erwartungen einerseits unfassbar freudig, andererseits einigermaßen undifferenziert: Zehn unbekannte Frauen, das gechillteste Hotel ever und zwei durchgeknallte Kommunikationstrainerinnen … … da konnte ja nicht viel schief gehen! Die fabulösen TalkTalks Lucienne Bangura-Nottbeck und Stefanie Fehr-Hoberg hatten zum viertätigen…
-
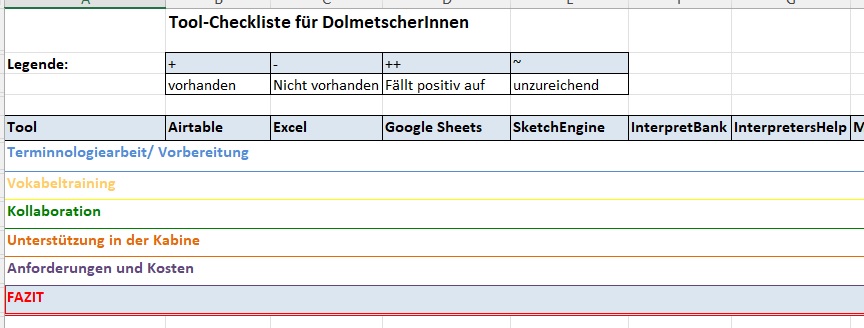
Checklist table of useful terminology tools for interpreters
Do you sometimes wonder which tools best serve your purpose as a conference interpreter? Well, two of my pollitos did, and they came up with this very handy and detailed checklist. It shows all sorts of terminology, spreadsheet, and extraction tools with their pros and cons. Thanks a lot to Eliana Cajas Balcazar y Vanessa…
-

Document management tools – the nerdy, the geeky, and the classic
When it comes to handling heaps of documents on one single screen (or two or three), I just can’t decide which document management program best serves my purpose. So I thought it might be useful to give a short overview of my top three, OneNote, LiquidText, and PDF XChange Editor, with their pros and cons…
-
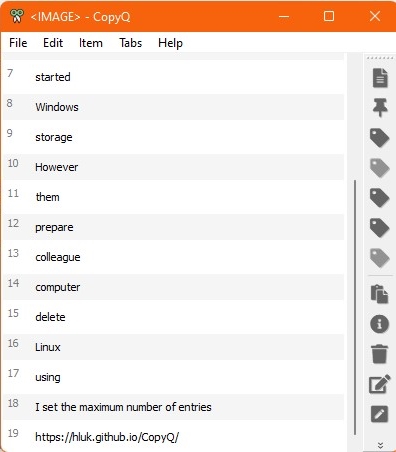
Use your clipboard for easier glossary building
When I prepare for a conference, I like to add expressions to a list and then look up equivalents, sort and categorise them later. But the other day I was so fed up with hopping back and forth between my glossary file and the pdfs, webpages etc. I was browsing in preparation (plus my colleague…
-

Tagesschau-Podcast: Mal angenommen … wir verstünden alle Sprachen
Aus der wunderbaren Zukunfts-Podcast-Reihe “Mal angenommen” diesmal eine Folge zum Thema Sprachen von Birthe Sönnichsen und Markus Sambale. Vielen herzlichen Dank, Markus Sambale (@medienmann), für ein durchaus inspirierendes Interview! War ja klar, dass “wir haben sie bei den Eiern” es in den Podcast schafft 😉 Neben meiner Wenigkeit auch zu hören Prof. Hans Uszkoreit und…
-

My hands-, eyes- and ears-on experience with SmarTerp, including a short interview with the UI designer
Last December, I was among the lucky ones who could beta-test SmarTerp, a CAI (Computer-Aided Interpreting) tool in development that offers speech-to-text support to simultaneous interpreters in the booth. For those who haven’t heard of SmarTerp before, this is what it is all about: SmarTerp comprises two components: 1. An RSI (Remote Simultaneous Interpreting) platform,…
-

Die Welt steht kopf, der Weihnachtsbaum auch #UpsideDownChristmasTree
Die Welt steht kopf – aber was soll’s? Der Weihnachtsbaum kann das schon lange. Schon vor über 200 Jahren hängte man den Christbaum gerne an die Zimmerdecke. In früheren Zeiten wohl eher, weil die Stube nicht so viel Platz bot, vielleicht auch, damit Kinder, Tiere und andere ungeschickte Hausbewohner ihn nicht umstießen. Im Mittelalter sei…
-
Here comes my first-AI written blog post
I was feeling a bit lazy today, so I thought I might give Artificial Intelligence a try. And here we go, this is my first blog post written by an AI writing assistant: How to Use the Best Interpreting Technology Translation and interpreting services are crucial for business success. If you’re a business owner, it…
-
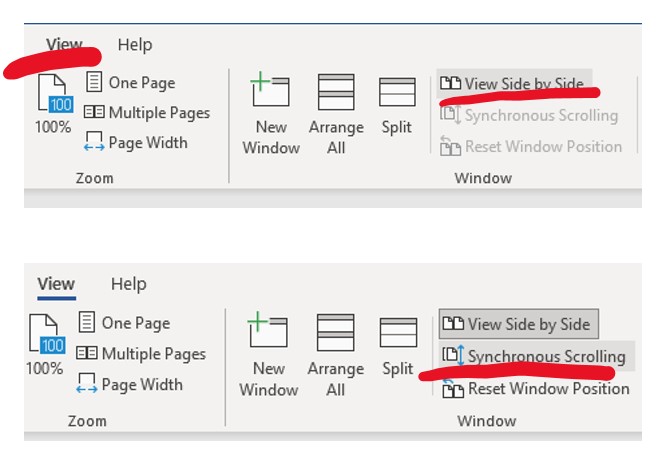
Synchronous Scrolling in Microsoft Word
Whilst it usually is fancy new apps designed for the benefit of interpreters (or everybody) that get my attention, this time it was boring old Microsoft Word I got excited about. Maybe I am the last one to discover the synchronous scrolling function, but I liked it so much that I wanted to share it.…
-

How to keep your glossaries as tidy as your kitchen drawer
Once again, the new semester is approaching, and another knowledge management course is about to start at TH Köln’s Master of Conference Interpreting. Now after 15 years of teaching, I find myself wondering what it is that I really really want my students to remember for the rest of their professional lives. Things have changed…
-

The pivot to remote online teaching on the MA in Conference Interpreting in Cologne: Lessons learned from an unexpected experience
This paper describes and critically evaluates the new online setting encountered when the MA in Conference Interpreting at the Institute of Translation and Multilingual Communication at TH Köln – University of Applied Sciences, Cologne, was forced to move completely online as a result of the COVID-19 pandemic. The pedagogical and interactional challenges of the pivot…
-

10 or so books every conference interpreter should read
I was told that bucket lists are key to successful blogging – so here is mine. 10 or so books every conference interpreter should read: The Bible (in all your working languages) Maschinenelemente für Dummies (machine parts for dummies) Chemie Kompaktwissen iIntroduction to chemistry) The Times Complete History of the World International Financial Reporting Standards…
-

Hard consoles – Quick guide to old normal relais interpreting
This blog post is intended for all those students who started their studies of conference interpreting right after the outbreak of Covid-19. More than one year into the pandemic, many of them haven’t entered a physical booth or put their hands on a hard console yet. In order to not leave them completely unprepared, I…
-

Gendern eigentlich Dolmetscher*innen?
Beim Dolmetschen gendern – das habe ich bislang eigentlich ganz munter “nach Gefühl” gehandhabt. Klar, wenn die Rednerin oder der Redner der Ausgangssprache gendert, übernehme ich das in der Zielsprache – sofern die sprachlichen Mittel das hergeben. Aber wenn die Originalsprache etwa Englisch ist, ist die Lage häufig alles andere als klar. Viele Benennungen erfordern…
-

No paper, no travel – can we get any greener these days?
No more traveling, paper coffee cups and the like … instead it’s videoconference interpreting, paperless office, and paperless booth (or no booth at all, for that matter) … so could we be any more eco-friendly at all? We could indeed – after all, we are generating tons of digital waste in our “new normal” everyday…
-

New normal conferences – virtual or in person?
One year into the pandemic, I thought it might be time to think about what our new normal work environment as conference interpreters will look like. Will new normal meetings and conferences return to the “real world”, or will most of them remain virtual? I very much hope that our new reality brings the best…
-

How to be boothmates without sharing a booth – My impressions from the #Innov1nt Summit 2021
Just in case you missed out on last week’s Innovation In Interpreting Summit by @adrechsel and @Goldsmith_Josh, aka Techforword, here comes my short and personal recap. The good news is: If you want to watch all the panels and loads of useful video contributions around how technology can support you in the booth, setting up your…
-
Save the Date – Innovation in Interpreting Summit – February 23-25, 2021
Looking forward to talking about How to be boothmates without sharing a booth on the Innovation in Interpreting Summit, hosted by our two favourite tech geeks, Josh Goldsmith & Alex Drechsel, aka @techforword. Registration for free tickets will start soon! Hope to see you there on 23-25 February 🙂 Anja About the author Anja Rütten…
-
Wishing you Happy Holidays and plenty of time for coffee breaks
-

The Unfinished Handbook for Remote Simultaneous Interpreters
Together with Angelika Eberhardt and Peter Sand, I have compiled tips and tricks around remote simultaneous interpreting (be it from a hub or from home) that we have been collecting ourselves or that colleagues have shared with us. It is meant as an informal collection of personal experiences that work for some while others may…
-
Natural Language Processing – What’s in it for interpreters?
“Natural Language Processing? Hey, that’s what I do for a living!” That’s what I thought when I heard about the live talk “A Glimpse at the Future of NLP” (big thank you to Julia Böhm for pointing this out to me). As I am always curious about what happens in AI and language processing, I…
-

Will 3D audio make remote simultaneous interpreting a pleasure?
Now THAT’S what I want: Virtual Reality for my ears! Apparently, simultaneous interpreters are not the only ones suffering from Zoom fatigue, i.e. the confusion and inability to physically locate a speaker using our ears can lead to a condition that’s sometimes referred to as “Zoom Fatigue”. But it looks like there is still reason…
-

Ein Hoch auf den guten Ton beim hybriden #DfD2020 | Good sound and vibes at Interpreters for Interpreters Workshop
+++ for English version see below +++ In einer Mischung aus ESC (“Hello from Berlin”) und Abiprüfung (getrennte Tische) hat am heutigen 18. Juli 2020 der bislang teilnehmerstärkste Dolmetscher-für-Dolmetscher-Workshop als Hybridveranstaltung in Bonn stattgefunden. 169 Dolmetscher*innen waren angemeldet, davon 80 Dolmetscher corona-konform persönlich vor Ort. Dies alles organisiert vom Fortbildungs-Dreamteam der AIIC Deutschland, Inés de…
-

You can never have too many screens, can you?
I don’t know about you, but I sometimes struggle, when using my laptop in the booth, to squeeze the agenda, list of participants, glossary, dictionary, web browser and meeting documents/presentations onto one screen. Not to mention email, messenger or shared notepad when working in separate booths in times of COVID-19 … Or even the soft…
-
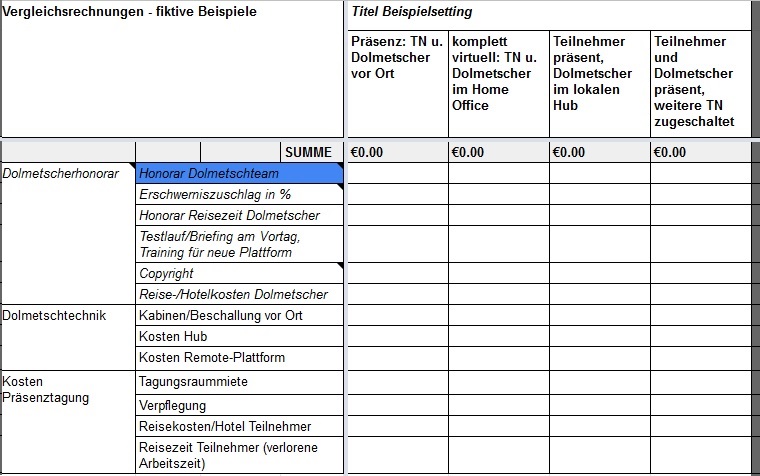
Was kostet Remote-Dolmetschen und warum?
Wann ist es sinnvoll, mit Dolmetschern vor Ort zu tagen, und wann ist Dolmetschen über das Internet sinnvoll? Nach unserem Web-Meeting der AIIC Deutschland am vergangenen Freitag (22. Mai 2020) mit dem herzerfrischenden Titel “TACHELES – RSI auf dem deutschen Markt” teile ich hier gerne mit Euch meine in eine rechnende Tabelle gegossenen Überlegungen zum…
-
Videos on fee calculation for conference interpreters | Videos sobre como calcular honorarios para intérpretes de conferencias
My tutorials on how to use the Time&money calculator, an Excel spreadsheet developed by AIIC Germany’s former profitability working group, finally have English and Spanish subtitles! Comments and questions welcome 🙂 Video on calculating working hours and fees for conference interpreters | Video sobre como calcular horas de trabajo y honorarios para intérpretes de conferencias…
-

Simultaneous interpreting in the time of coronavirus – Boothmates behind glass walls
Yesterday was one of the rare occasions where conference interpreters were still brought to the client’s premises for a multilingual meeting. Participants from abroad were connected via a web meeting platform, while the few people who were on-site anyway were sitting at tables 2 meters apart from each other. But what about the interpreters, who…
-

How to Make CAI Tools Work for You – a Guest Article by Bianca Prandi
After conducting research and providing training on Computer-Assisted Interpreting (CAI) for the past 6 years, I feel quite confident in affirming that there are three indisputable truths about CAI tools: they can potentially provide a lot of advantages, do more harm than good if not used strategically, and most interpreters know very little about them.…
-

Preparing on numbers: Yes, we CAN (and SHOULD)! – A Guest Article by Francesca Maria Frittella
A new client requested you to interpret at his business’s annual press conference. It’s quite a big assignment and the event takes place in only five days, but you are not worried: the best practices that you have developed through your training and professional experience allow you to prepare efficiently and effectively. So, you get…
-

Vögelchen füttern nicht vergessen! | Don’t forget to feed the birds! | ¡No se olviden de dar de comer a los pajaritos!
Frohe Festtage! * ¡Felices Fiestas! * Happy Holidays! * Joyeuses Fêtes!
-

#multitalkingfähig – Eindrücke vom BDÜ-Kongress 2019 in Bonn
Das Potpourri aus über 100 Vorträgen, Diskussionen, Seminaren und Workshops, das der BDÜ vergangenes Wochenende beim BDÜ-Kongress in Bonn hingezaubert hat, kann ein einzelner Mensch gewiss nicht würdigen. Deshalb ist mein kleiner Bericht auch nur ein ganz persönlicher Erfahrungsausschnitt. Sämtliche Abstracts und Artikel lassen sich viel besser im Tagungsband nachlesen. Mein erster Gedanke auf dem…
-

DeepL – not too bad, even if it turns marriage into war
After Microsoft Translate and Google Translate, last week I decided to take a closer look at DeepL‘s beta desktop application. I had to prepare over 50 Power Point slides filled with text about quite a number of rulings of the European Court of Justice. I was pretty sure these would be read out at high…
-
Deliberate Practice – What’s in it for Conference Interpreters
The one thing that strikes me most about deliberate practice is the notion of immediate feedback. How could that possibly work in simultaneous interpreting? You can’t just interrupt each other when interpreting, can you? Well, most certainly not while on the job, but could you give immediate feedback when practising in a silent booth or…
-

Neues vom Dolmetscher-für-Dolmetscher-Workshop in Bonn #aiicDfD2019
Die Sommerpause 2019 geht dem Ende entgegen, Zeit also für den traditionell von der AIIC Deutschland organisierten Workshop Dolmetscher für Dolmetscher. 71 Dolmetscherinnen und Dolmetscher haben am heutigen 31. August bei mindestens 31 Grad Außentemperatur in Bonn den ganzen Tag über Themen rund um das “Konferenzdolmetschen 4.0” diskutiert. Eine vollständige Zusammenfassung des Tages gibt es…
-

Remote Simultaneous Interpreting … muss das denn sein – und geht das überhaupt?!
In einem von AIIC und VKD gemeinsam organisierten Workshop unter der Regie von Klaus Ziegler hatten wir Mitte Mai in Hamburg die Gelegenheit, diese Fragen ausführlich zu ergründen. In einem Coworkingspace wurde in einer Gruppe organisierender Dolmetscher zwei Tage lang gelernt, diskutiert und in einem Dolmetschhub das Remote Simultaneous Interpreting über die cloud-basierte Simultandolmetsch-Software Kudo…
-

Great Piece of Research on Terminology Assistance for Conference Interpreters
-

No me canso, ganso – mis impresiones del Foro Lenguas 2019 en CDMX
En medio del desabasto de gasolina llegué a la ciudad de México para asistir al Foro Lenguas 2019 la semana pasada. En este congreso, con representación de 20 lenguas amerindias y 7 lenguas extranjeras, me lancé a la aventura para discutir la gramática, la importancia de las asociaciones profesionales y el papel que desempeñan las…