[Dolmetscher wissen alles] Interpreters know everything
A blog on knowledge & conference interpreting
-

Eight rules to get the most out of live translation apps
This month at the Technical University of Cologne we took a closer look at some live translation apps, in particular Galaxy’s live translation app for phone calls. Prof. Ralph Krüger and I, together with journalist Steffen Berner, wanted to find out how useful they are. It was both an interesting and entertaining experience. Obviously, nothing…
-

Recap of VKD’s round table discussion on artificial intelligence
As promised, here comes the English version of my article published in the German conference interpreters’ association (VKD im BDÜ e.V.) bulletin “VKD-Kurier“ in December 2023 Quo Vadis yet again? On 17 October 2023, VKD hosted a virtual round table discussion on AI. I was invited to give a keynote speech – a dubious honour…
-

Meet Truedee, my ChatGPT based preparation assistant
So ChatGPT now lets you create your own custom ChatGPT using OpenAI’s no-code platform GPT builder … about time, I thought, to give it a try and create my own chatty conference preparation assistant, TrueDee. It/she/he is available at this link, so feel free to get acquainted. We are not exactly soulmates yet, as TrueDee…
-

Season’s greetings from paradise * Paradiesische Feiertage * Unas fiestas paradisíacas * Des fêtes paradisiaques
(if you can’t open the short video, click here) Die ersten Weihnachtsbäume wurden schon im 15. Jahrhundert mit Früchten und Nüssen geschmückt. Unter anderem wurden Äpfel an den Baum gehängt, die an die verbotene Frucht des Baumes der Erkenntnis erinnerten. Nicht umsonst haben Adam und Eva am 24. Dezember Namenstag. So steht der Apfel für…
-
Nachlese zum Runden Tisch des VKD im BDÜ zum Thema Künstliche Intelligenz
Artikel aus dem VKD-Kurier Dezember 2023 [English version here] Quo vadis denn jetzt schon wieder? Am 17. Oktober 2023 lud der VKD zum virtuellen Runden Tisch in Sachen KI ein. Mir wurde die Ehre zuteil, ein Impulsreferat halten zu dürfen – für meine Begriffe eine zweifelhafte Ehre, weil in meinem Kopf über allen Fragen rund…
-
Live transcription in RSI with Otter.ai and Airgram.io
Yesterday, in a Remote Simultaneous Interpreting team with colleagues being distributed all over Europe, it suddenly occurred to us to play around a bit with live transcription as a support (thanks to Mike Morandin’s innocent question if anyone had ever used it). No sooner said than done – within a few minutes our wonderful chef…
-

The InterpretBank Artificial Boothmate in action | guest article by Benjamin Gross
As interpreters, we’re used to being team players. We don’t like to work alone – whether that be in a booth on-site or remotely from our home offices. Whatever we do, we can trust our favourite people – our booth mates. So what if we could have an additional mate in our booth? A mate…
-
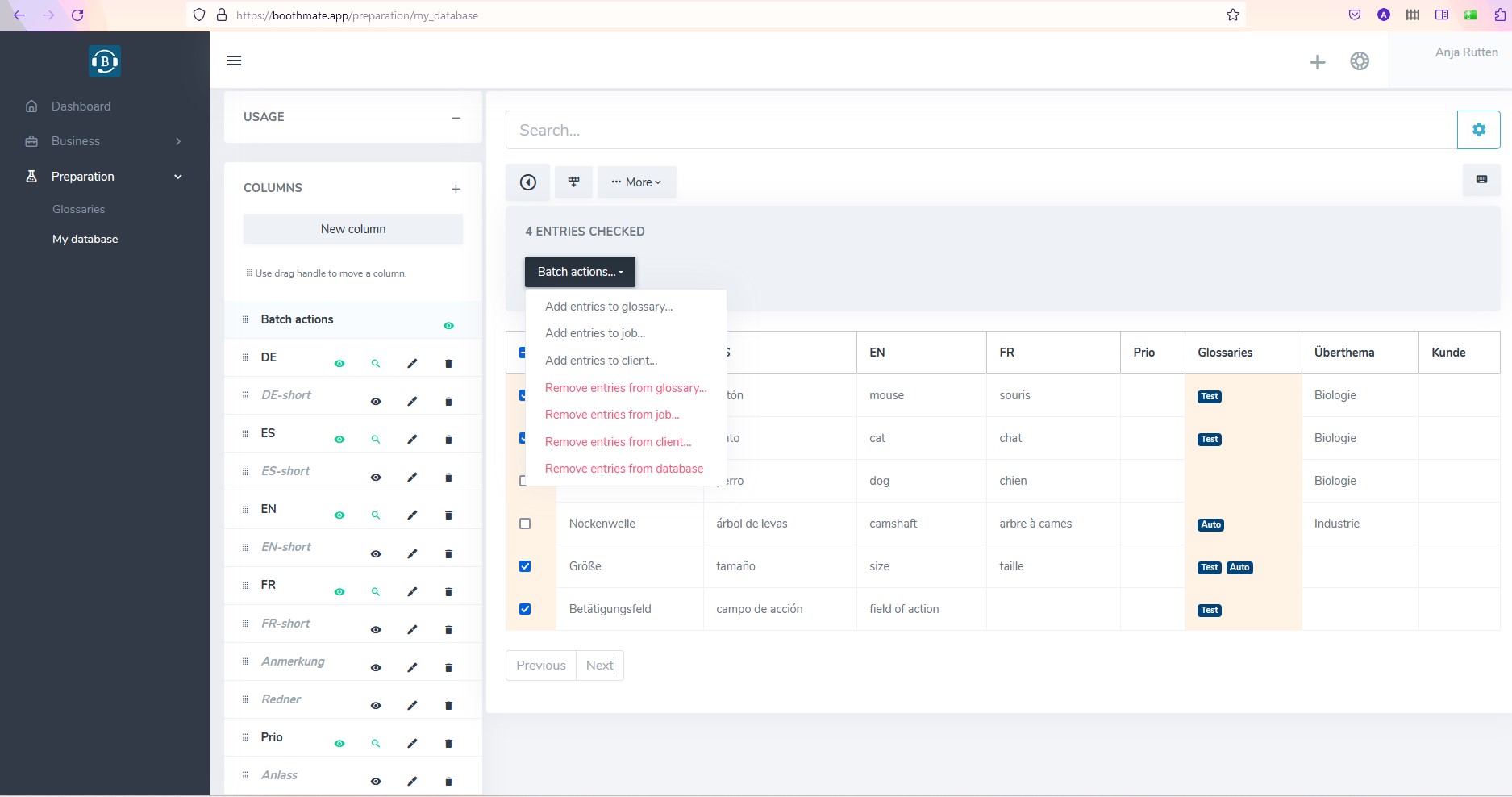
New (beta) version of Interpretershelp with lots of great new features to discover ️- now available at boothmate.app
InterpretersHelp is a very straightforward browser-based terminology and job management application that allows for secure online collaboration. It is great for keeping your terminology up to date on all devices and sharing it with colleagues. It has been around for about ten years now, reason enough for Benoit Werner, co-founder and technical brain of this…
-

Chatting with Lourdes de Rioja about AI, professional domiciles, economic literacy, blogging, and the relevance of information
Being asked the right questions by the right person can be so inspiring … thank you very much to the great Lourdes de Rioja for chatting with me about AI, professional domiciles, economic literacy, blogging, and the relevance of information. *** Fue un placer enorme ser entrevistada por la gran Lourdes de Rioja. ¡Cuán inspirador puede…
-

What’s conference interpreting after all?
How to define “conference interpreting” We will be celebrating AIIC’s 70th anniversary in July. Earlier this year, we celebrated the German VKD’s 20th anniversary in Berlin, where I handed over the responsibility of chairing the VKD admissions committee. Both occasions as well as many inspiring conversations I have had recently left me musing about a…
-
How to tell a chatbot like ChatGPT or Sage to align texts in different languages in a table (and besides get a summary )
If you have the same text in several languages and you want the different versions neatly arranged in a table with the sentences in the different language versions next to each other, a chatbot like ChatGPT may be able to help. Especially when texts come in pdf format, just copying and pasting them can already…
-
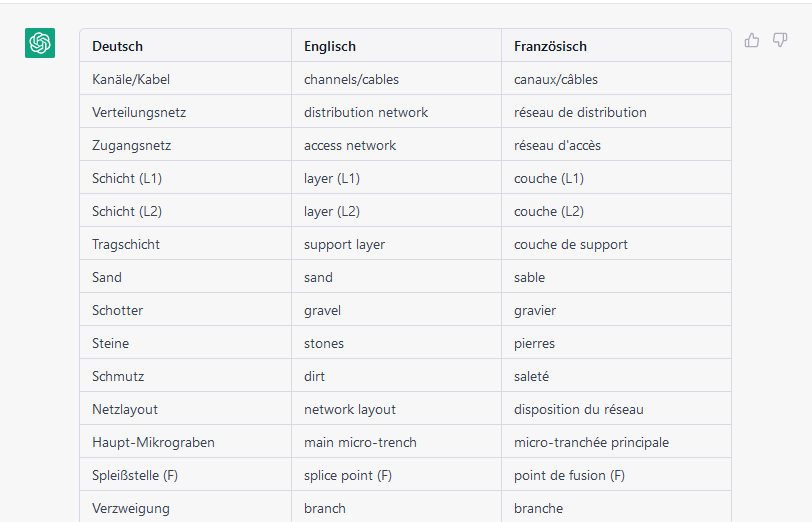
How to tell ChatGPT to extract terminology from parallel texts in different languages
My dear colleague (and former student) Florian Pfaffelhuber just drew my attention to the fact that ChatGPT is great at multilingual terminology extraction. It can also handle more than two languages and will create very nice multilingual glossary tables for you. What worked best when we tested it today was to copy the prompt and…
-

Use ChatGPT, DeepL & Co. to boost your conference preparation
In this article I would like to show you how I like to use DeepL, Google Translate, Microsoft Translator, and ChatGPT as a conference interpreter, especially in conference preparation. You will also see how to use GT4T to combine the different options. I did some testing for this year’s Innovation in Interpreting Summit and I…
-

Cognitive sustainability for conference interpreters (and other high intensity knowledge workers)
Cognitive sustainability Flight-shaming, banning fast fashion, upcycling old milk cartons, taking financial precautions for when we are old or a pandemic strikes – it’s sustainability all around. But what about our most precious working resource – our brain? Is “cognitive sustainability” a thing at all? Sustainability There are many definitions of sustainability. Although originally coined…
-

Kognitive Nachhaltigkeit bei der Wissensarbeit
Kognitive Nachhaltigkeit Es begab sich in diesem Januar 2023 vor dem Dolmetscher-für-Dolmetscher-Workshop (#dfd2023, organisiert durch das fabelhafte Fortbildungsteam von @aiic_de), der sich dem übergroßen Thema der Nachhaltigkeit verschrieben hatte, dass ich mir Gedanken machte zu der Frage, wie kognitiv nachhaltig wir eigentlich sind. Wie es sich gehört, stand am Anfang die Frage: Was ist das…
-
Everyone deserves a bit of tinsel ✨ Jeder verdient ein bisschen Lametta ✨ Todos nos merecemos un poco de oropel
2022 war für mich das Jahr der wundervollen Begegnungen. Mögen alle, die sich hiervon angesprochen fühlen, und auch alle anderen sich mit Glanz und Gloria gefeiert fühlen! 2022 was my year of wonderful encounters. So here’s to all those I shared real or virtual moments with, and to everyone else! May you all feel celebrated…
-
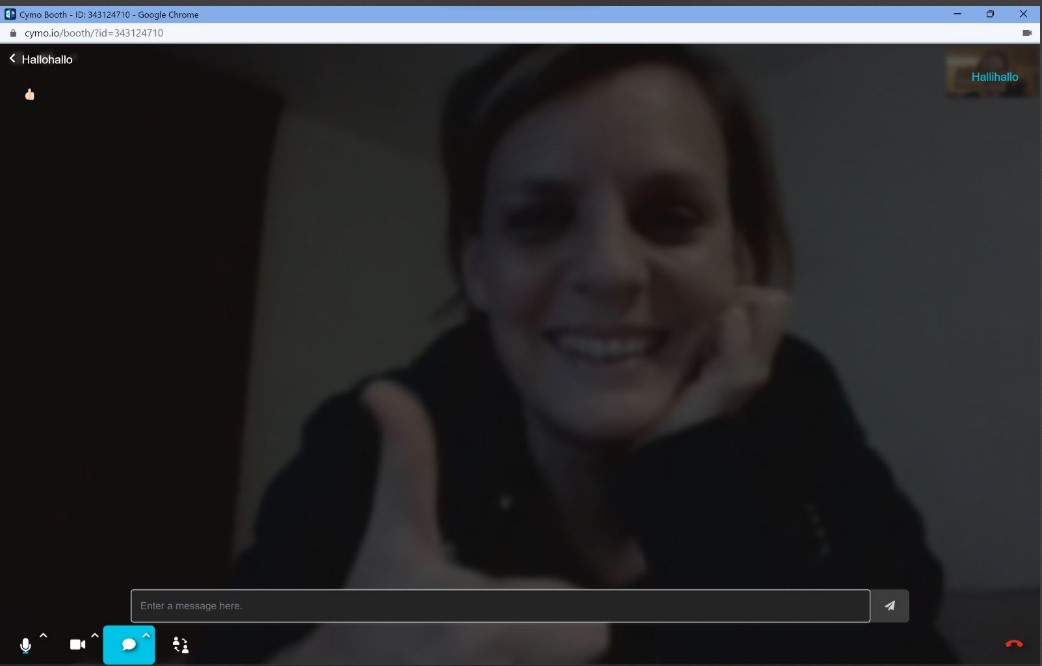
Cymo booth – great, easy-to-use private booth channel for interpreters on Zoom
When Peter Sand mentioned Cymo Booth recently as a solution to having a private video/audio/chat channel with your remote boothmate while interpreting on Zoom, my spontaneous reaction was “Oh no, not another video channel on my already over-crowded screen …” But luckily, Angelika Eberhardt talked me into trying it nonetheless. Or rather, she simply sent…
-

Automatic bilingual term extraction with OneClickTerms by SketchEngine
When I wrote about this great terminology extraction tool OneClickTerms back in 2017 I was already quite enthusiastic about how useful it was for last-minute conference preparation. But the one thing I didn’t mention back then (or maybe it wasn’t available yet) was that OneClickTerms does not only extract terminology from monolingual documents, but it…
-

Computer mouse – old buddy with new talents
I wouldn’t normally expect much more from a computer mouse than right click, left click, double click, scroll. But I was taught better recently. Among the slightly younger generation (i.e., my kids), rather bulky and gaming-type models seem to be in vogue lately also for office (ie.,school) work. Not exactly made for traveling in your…
-

The new IATE interpreters’ view – what’s in it for EU meeting preparation?
The EU’s terminology database has been around for quite some time – the project was launched back in 1999 and has been available to the public since 2007. Recently, it has been revamped, and an “interpreters’ view” has been added. All EU interpreters, staff and freelancers alike, have access to it, and it is tailored…
-

Some thoughts on the importance of trust in conference interpreting | by Karin Walker and Anja Rütten
The first time I (Anja) worked with somebody I only knew virtually, without any personal connections or references, was back in 2001, still in times of the Deutsche Mark: I worked on a Spanish translation project together with a complete stranger, a colleague I made contact with via an electronic mail list for translators. We…
-

Meine erste Workation – über Vertrauen im Dolmetschberuf und Pausen in Pink
Als ich mich vor einem Monat auf nach Rhodos zur ersten Workation meines Lebens machte, waren meine Erwartungen einerseits unfassbar freudig, andererseits einigermaßen undifferenziert: Zehn unbekannte Frauen, das gechillteste Hotel ever und zwei durchgeknallte Kommunikationstrainerinnen … … da konnte ja nicht viel schief gehen! Die fabulösen TalkTalks Lucienne Bangura-Nottbeck und Stefanie Fehr-Hoberg hatten zum viertätigen…
-
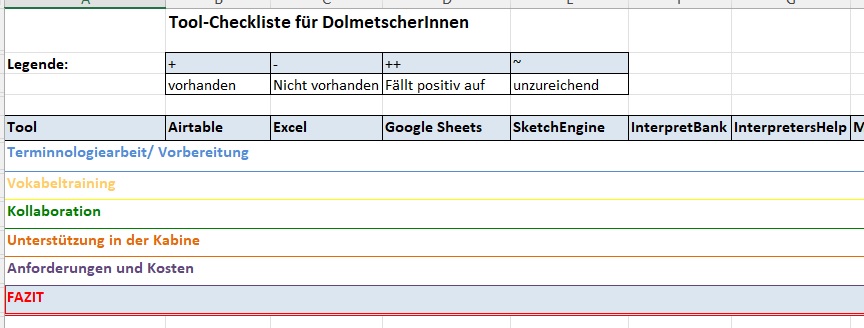
Checklist table of useful terminology tools for interpreters
Do you sometimes wonder which tools best serve your purpose as a conference interpreter? Well, two of my pollitos did, and they came up with this very handy and detailed checklist. It shows all sorts of terminology, spreadsheet, and extraction tools with their pros and cons. Thanks a lot to Eliana Cajas Balcazar y Vanessa…
-

Document management tools – the nerdy, the geeky, and the classic
When it comes to handling heaps of documents on one single screen (or two or three), I just can’t decide which document management program best serves my purpose. So I thought it might be useful to give a short overview of my top three, OneNote, LiquidText, and PDF XChange Editor, with their pros and cons…
-
Use your clipboard for easier glossary building
When I prepare for a conference, I like to add expressions to a list and then look up equivalents, sort and categorise them later. But the other day I was so fed up with hopping back and forth between my glossary file and the pdfs, webpages etc. I was browsing in preparation (plus my colleague…
-

Tagesschau-Podcast: Mal angenommen … wir verstünden alle Sprachen
Aus der wunderbaren Zukunfts-Podcast-Reihe “Mal angenommen” diesmal eine Folge zum Thema Sprachen von Birthe Sönnichsen und Markus Sambale. Vielen herzlichen Dank, Markus Sambale (@medienmann), für ein durchaus inspirierendes Interview! War ja klar, dass “wir haben sie bei den Eiern” es in den Podcast schafft 😉 Neben meiner Wenigkeit auch zu hören Prof. Hans Uszkoreit und…
-

My hands-, eyes- and ears-on experience with SmarTerp, including a short interview with the UI designer
Last December, I was among the lucky ones who could beta-test SmarTerp, a CAI (Computer-Aided Interpreting) tool in development that offers speech-to-text support to simultaneous interpreters in the booth. For those who haven’t heard of SmarTerp before, this is what it is all about: SmarTerp comprises two components: 1. An RSI (Remote Simultaneous Interpreting) platform,…
-

Die Welt steht kopf, der Weihnachtsbaum auch #UpsideDownChristmasTree
Die Welt steht kopf – aber was soll’s? Der Weihnachtsbaum kann das schon lange. Schon vor über 200 Jahren hängte man den Christbaum gerne an die Zimmerdecke. In früheren Zeiten wohl eher, weil die Stube nicht so viel Platz bot, vielleicht auch, damit Kinder, Tiere und andere ungeschickte Hausbewohner ihn nicht umstießen. Im Mittelalter sei…
-
Here comes my first-AI written blog post
I was feeling a bit lazy today, so I thought I might give Artificial Intelligence a try. And here we go, this is my first blog post written by an AI writing assistant: How to Use the Best Interpreting Technology Translation and interpreting services are crucial for business success. If you’re a business owner, it…
-
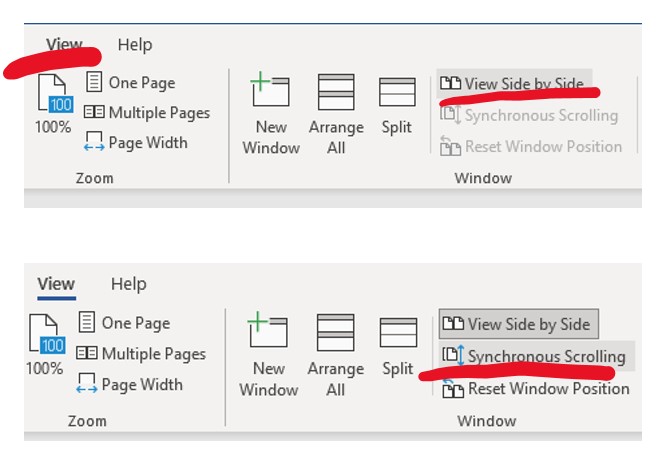
Synchronous Scrolling in Microsoft Word
Whilst it usually is fancy new apps designed for the benefit of interpreters (or everybody) that get my attention, this time it was boring old Microsoft Word I got excited about. Maybe I am the last one to discover the synchronous scrolling function, but I liked it so much that I wanted to share it.…
-

How to keep your glossaries as tidy as your kitchen drawer
Once again, the new semester is approaching, and another knowledge management course is about to start at TH Köln’s Master of Conference Interpreting. Now after 15 years of teaching, I find myself wondering what it is that I really really want my students to remember for the rest of their professional lives. Things have changed…
-

The pivot to remote online teaching on the MA in Conference Interpreting in Cologne: Lessons learned from an unexpected experience
This paper describes and critically evaluates the new online setting encountered when the MA in Conference Interpreting at the Institute of Translation and Multilingual Communication at TH Köln – University of Applied Sciences, Cologne, was forced to move completely online as a result of the COVID-19 pandemic. The pedagogical and interactional challenges of the pivot…
-

10 or so books every conference interpreter should read
I was told that bucket lists are key to successful blogging – so here is mine. 10 or so books every conference interpreter should read: The Bible (in all your working languages) Maschinenelemente für Dummies (machine parts for dummies) Chemie Kompaktwissen iIntroduction to chemistry) The Times Complete History of the World International Financial Reporting Standards…
-

Hard consoles – Quick guide to old normal relais interpreting
This blog post is intended for all those students who started their studies of conference interpreting right after the outbreak of Covid-19. More than one year into the pandemic, many of them haven’t entered a physical booth or put their hands on a hard console yet. In order to not leave them completely unprepared, I…
-

Gendern eigentlich Dolmetscher*innen?
Beim Dolmetschen gendern – das habe ich bislang eigentlich ganz munter “nach Gefühl” gehandhabt. Klar, wenn die Rednerin oder der Redner der Ausgangssprache gendert, übernehme ich das in der Zielsprache – sofern die sprachlichen Mittel das hergeben. Aber wenn die Originalsprache etwa Englisch ist, ist die Lage häufig alles andere als klar. Viele Benennungen erfordern…
-

No paper, no travel – can we get any greener these days?
No more traveling, paper coffee cups and the like … instead it’s videoconference interpreting, paperless office, and paperless booth (or no booth at all, for that matter) … so could we be any more eco-friendly at all? We could indeed – after all, we are generating tons of digital waste in our “new normal” everyday…
-

New normal conferences – virtual or in person?
One year into the pandemic, I thought it might be time to think about what our new normal work environment as conference interpreters will look like. Will new normal meetings and conferences return to the “real world”, or will most of them remain virtual? I very much hope that our new reality brings the best…
-

How to be boothmates without sharing a booth – My impressions from the #Innov1nt Summit 2021
Just in case you missed out on last week’s Innovation In Interpreting Summit by @adrechsel and @Goldsmith_Josh, aka Techforword, here comes my short and personal recap. The good news is: If you want to watch all the panels and loads of useful video contributions around how technology can support you in the booth, setting up your…
-
Save the Date – Innovation in Interpreting Summit – February 23-25, 2021
Looking forward to talking about How to be boothmates without sharing a booth on the Innovation in Interpreting Summit, hosted by our two favourite tech geeks, Josh Goldsmith & Alex Drechsel, aka @techforword. Registration for free tickets will start soon! Hope to see you there on 23-25 February 🙂 Anja About the author Anja Rütten…
-
Wishing you Happy Holidays and plenty of time for coffee breaks