Tag: simultaneous interpreting
-

Bilingual songs, cloze texts, emotional EU debates, texts with numbers – some creative chatbot prompts for conference interpreting practice
This year, both myself and my students at MAKD were quite inspired when it came to using AI to generate creative interpreting exercises. So I thought I might share some examples for other interpreting students, teachers, and professionals to use. And of course, feel free to share other examples of AI-supported exercises for student interpreters…
-

Privacy, sensitive data, intellectual property – what’s there to protect in times of AI
No matter if we use AI to support or even replace translators, interpreters, or any other profession, there is always that “legal” question lingering in my – and seemingly everybody’s – mind: Is “the AI” being trained on my voice, my translation, my ideas? Will sensitive information end up in this black box LLM and…
-

Getting to know Boothie, the University of Gent’s CAI project
The Ergonomics for the Artificial Booth Mate (EABM) project conducted at the University of Ghent has been catching my attention for a while, with all these experiments on cognitive load in the booth run by Bart Defrancq. The CAI tool associated with the project, Boothie, provides live-prompting of terms and numbers in the booth along…
-

Live prompting CAI tools – a market snapshot
In the aftermath of our inspiring AIIC AI Day in Rome, I felt that an overview of all live-prompting CAI (Computer-Assisted Interpreting) tools might be very much appreciated by many colleagues. So here we go – these are the tools providing live prompting of terms, numbers, names or complete transcripts in the booth during simultaneous…
-

Computer mouse – old buddy with new talents
I wouldn’t normally expect much more from a computer mouse than right click, left click, double click, scroll. But I was taught better recently. Among the slightly younger generation (i.e., my kids), rather bulky and gaming-type models seem to be in vogue lately also for office (ie.,school) work. Not exactly made for traveling in your…
-

Some thoughts on the importance of trust in conference interpreting | by Karin Walker and Anja Rütten
The first time I (Anja) worked with somebody I only knew virtually, without any personal connections or references, was back in 2001, still in times of the Deutsche Mark: I worked on a Spanish translation project together with a complete stranger, a colleague I made contact with via an electronic mail list for translators. We…
-

My hands-, eyes- and ears-on experience with SmarTerp, including a short interview with the UI designer
Last December, I was among the lucky ones who could beta-test SmarTerp, a CAI (Computer-Aided Interpreting) tool in development that offers speech-to-text support to simultaneous interpreters in the booth. For those who haven’t heard of SmarTerp before, this is what it is all about: SmarTerp comprises two components: 1. An RSI (Remote Simultaneous Interpreting) platform,…
-

Hard consoles – Quick guide to old normal relais interpreting
This blog post is intended for all those students who started their studies of conference interpreting right after the outbreak of Covid-19. More than one year into the pandemic, many of them haven’t entered a physical booth or put their hands on a hard console yet. In order to not leave them completely unprepared, I…
-

You can never have too many screens, can you?
I don’t know about you, but I sometimes struggle, when using my laptop in the booth, to squeeze the agenda, list of participants, glossary, dictionary, web browser and meeting documents/presentations onto one screen. Not to mention email, messenger or shared notepad when working in separate booths in times of COVID-19 … Or even the soft…
-

Simultaneous interpreting in the time of coronavirus – Boothmates behind glass walls
Yesterday was one of the rare occasions where conference interpreters were still brought to the client’s premises for a multilingual meeting. Participants from abroad were connected via a web meeting platform, while the few people who were on-site anyway were sitting at tables 2 meters apart from each other. But what about the interpreters, who…
-

Great Piece of Research on Terminology Assistance for Conference Interpreters
-

What do conference interpreters’ booth notes tell us about their information management?
First of all, a big thank you to all of you who followed my call and provided copies of their booth notes for my little study – I finally managed to collect booth notes from 25 colleagues! Now, what was this study all about? The purpose was to see what interpreters write down intuitively on…
-
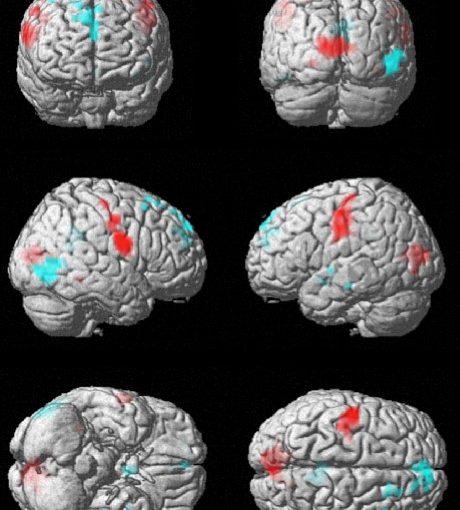
Neurophysiologie des Simultandolmetschens | Neurophysiology of simultaneous interpreting – by Eliza Kalderon
+++ for English, scroll down +++ Etwa eineinhalb Jahre nach Beenden der Promotion freue ich mich über die Möglichkeit, im Blog meiner Kollegin, die das Projekt “Neurophysiologie des Simultandolmetschens: eine fMRI-Studie mit Konferenzdolmetschern” von Anfang an voller Begeisterung und Engagement unterstützte, eines der spannendsten Ergebnisse vorstellen zu dürfen. Die drei nachfolgenden Abbildungen stellen sogenannte Render-Bilder…
-
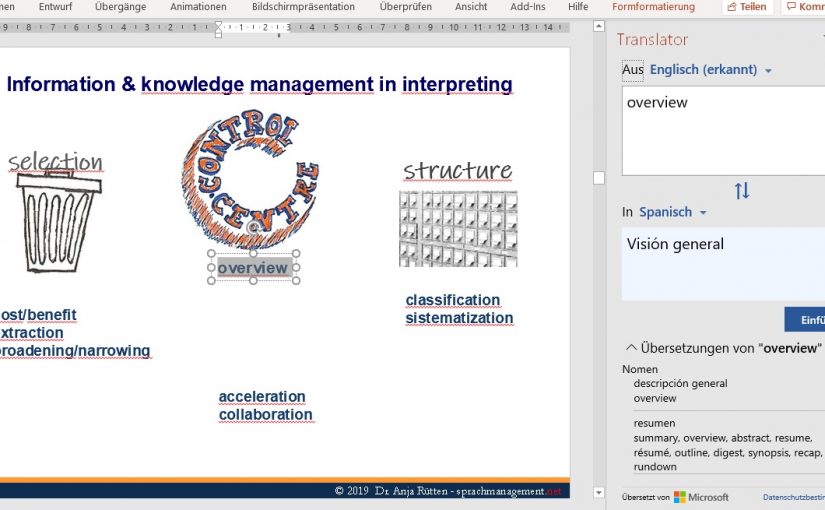
Microsoft Office Translator – Can it be of any help in the booth?
When it comes to Computer-Aided Interpreting (CAI), a question widely discussed in the interpreting community is whether information being provided automatically by a computer in the booth could be helpful for simultaneous interpreters or if would rather be a distraction. Or to put it differently: Would the cognitive load of simultaneous interpreting be increased by…
-

How to measure the efficiency of your conference preparation
Half of the time we dedicate to a specific interpreting assignment is often spent on preparation. But while many a thought is given to the actual interpreting performance and the different ways to evaluate it, I hardly ever hear anyone discuss their (or others’) preparation performance. However, if we want to be good information and…
-
InterpretersHelp’s new Practice Module – Great Peer-Reviewing Tool for Students and Grownup Interpreters alike
I have been wondering for quite a while now why peer feedback plays such a small role in the professional lives of conference interpreters. Whatwith AIIC relying on peer review as its only admission criterion, why not follow the logic and have some kind of a routine in place to reflect upon our performance every…
-

InterpretBank 4 review
InterpretBank by Claudio Fantinuoli, one of the pioneers of terminology tools for conference interpreters (or CAI tools), already before the new release was full to the brim with useful functions and settings that hardly any other tool offers. It was already presented in one of the first articles of this blog, back in 2014. So now…
-

Can computers outperform human interpreters?
Unlike many people in the translation industry, I like to imagine that one day computers will be able to interpret simultaneously between two languages just as well as or better than human interpreters do, what with artificial neuronal neurons and neural networks’ pattern-based learning. After all, once hardware capacity allows for it, an artificial neural…
-
Hello from the other side – Chinese and Terminology Tools. A guest article by Felix Brender 王哲謙
As Mandarin Chinese interpreters, we understand that we are somewhat rare beings. After all, we work with a language which, despite being a UN language, is not one you’d encounter regularly. We wouldn’t expect colleagues working with other, more frequently used languages to know about the peculiarities of Mandarin. This applies not least to terminology…
-

Digital dementia and conference interpreters – article published in Multilingual July/August 2015
To read this article on effects of digitalisation on conference interpreters’ memory and learning habits, please follow the link to multilingual.com (English only). —————- About the author Anja Rütten is a freelance conference interpreter for German (A), Spanish (B), English (C) and French (C) based in Düsseldorf, Germany. She has specialised in knowledge management…
-

Booth-friendly terminology management: Intragloss – the missing link between texts and glossaries|die Brücke zwischen Text und Glossar
+++ for English see below +++ Wer schon immer genervt war von der ständigen Wechselei zwischen Redetexten/Präsentationsfolien einerseits und dem Glossar andererseits, der hat jetzt allen Grund zu jubilieren: Dan Kenig und Daniel Pohoryles aus Paris haben mit Intragloss eine Software entwickelt, in der man direkt aus dem Text Termini in sein Glossar befördern kann…
-

Handschriftlich notieren oder tippen – was sagt die Forschung? | Handwriting vs. typing – what does research tell us?
+++ for English see below +++ Egal, in welchem Kreis von Dolmetschern man darüber redet, geschätzte 10 % schwören immer Stein und Bein, dass sie sich die Dinge besser merken können, wenn sie sie mit Stift und Papier festhalten. Sie pfeifen auch auf die Vorteile des papierlosen Büros, darauf, ihre Unterlagen durchsuchen und Glossare sortieren…
-
Booth-friendly terminology management – Flashterm.eu
+++ for English see below +++ Wer – womöglich auch fürs Übersetzen – eigentlich lieber eine “richtige” Terminologieverwaltung hätte, die obendrein aber noch kabinenfreundlich ist, der sollte einmal bei Flashterm von der Eisenrieth Dokumentations GmbH vorbeischauen. Flashterm basiert auf Filemaker und bietet die Klassiker der Eintragsmöglichkeiten wie Sachgebiete, Synonyme, Kontext usw. , aber auch das…
-
Mein Gehirn beim Simultandolmetschen| My brain interpreting simultaneously
+++ for English, see below +++ Für gewöhnlich fragen wir uns ja eher, was gerade um Himmels Willen im Kopf des Redners vorgeht, den wir gerade dolmetschen. Unsere Kollegin Eliza Kalderon jedoch stellt in ihrer Doktorarbeit die umgekehrte Frage: Was geht eigentlich in den Dolmetscherköpfen beim Simultandolmetschen vor? Zu diesem Zweck steckt sie Probanden in…
-

Not-To-Do Lists and Not-To-Learn Words
+++ For English see below +++ To-Do-Listen sind eine feine Sache: Einmal aufgeschrieben, kann man lästige Aufgaben zumindest zeitweilig des Gedächtnisses verweisen, und überhaupt ist man viel organisierter und effizienter. Ich zumindest gieße seit Ewigkeiten alles, was nicht bei drei auf den Bäumen ist, in eine Excel-Tabelle – seien es nun Geld, Arbeit, Adressbuch oder…
-
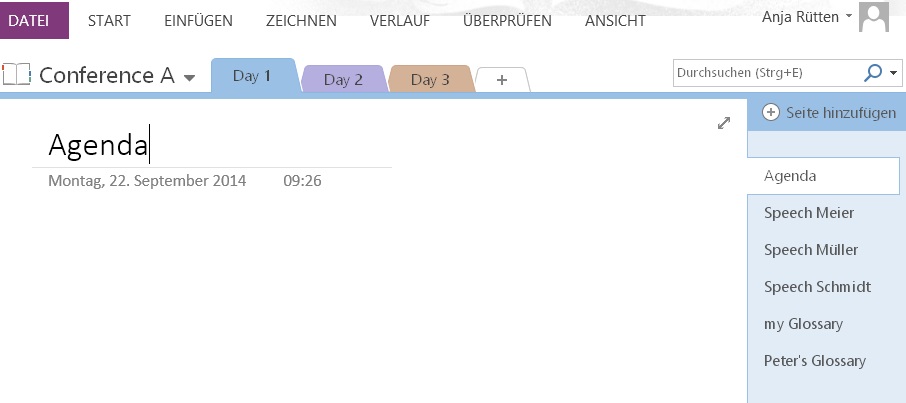
Organise your meeting documents with MS-OneNote – Sitzungsunterlagen perfekt im Zugriff mit Onenote
+++ for English see below +++ Warum scheuen viele Dolmetscher eigentlich davor zurück, völlig papierfrei in die Kabine zu gehen, und wechseln lieber zwischen einem Stapel ausgedruckter Dokumente auf der einen Seite und einem Computer als reine Vokabelsuchmaschine auf der anderen Seite hin und her? Ich vermute, der Grund ist dieser: Man kann einfach nie…
-

Do interpreters suffer from decision fatigue? – Entscheidungsmüdigkeit beim Dolmetschen?
+++ for English see below +++ Entscheidungen sind anstrengend. Chicken or Pasta, Sekt oder Selters, Windows oder Mac, vom Blatt dolmetschen oder frei – den ganzen Tag müssen wir uns entscheiden, und je mehr Entscheidungen sich aneinander reihen, desto entscheidungsmüder werden wir, desto weniger gründlich wägen wir die Möglichkeiten also ab oder bleiben im Zweifel…
-

Booth-friendly terminology management programs for interpreters – a market snapshot
– This one comes in English, as many non-German-speaking colleagues have asked for it. – This article is meant to give you a very brief overview of the terminology management programs that I am aware of (in alphabetical order), made for simultaneous interpreters. I have tried to highlight the merits and downsides that in my…