[for German scroll down] What do you do when you receive 100 pages to read five minutes before the conference starts? Right, you throw the text into a machine and get out a list of technical terms that give you a rough overview of what it’s all about. Now finally, it looks like this dream has come true.
OneClick Terms by SketchEngine is a browser-based (a big like) terminology extraction tool which works really swiftly. It has all it takes and nothing more (another big like): Upload – Settings – Results.
Once you are logged in for your free trial, OneClickTerms accepts the formats tmx, xliff (2.x), pdf, doc(x), html, txt. The languages supported are Czech, German, English, Spanish, French, Italian, Japanese, Korean, Dutch, Polish, Portuguese, Russian, Slovak, Slovenian, Chinese Simplified, Chinese Traditional.
The settings in my opinion don’t really need to be touched. They include:
- how rare or common should the extracted terms be
- would you like to see the word form as it appears in the text or the base form
- how often should a term candidate occur in the text in order to make it to the list of results
- do you want numbers to appear in your results
- how many terms should your list of results contain
When I tried OneClick Terms, it delivered absolutely relevant results at the first go. I uploaded an EU text on the free flow of non-personal data (pdf of about 100 pages) at about 8:55 am and the result I got at 8:57, displayed right on the same website, looked like this (and yes, the small W icons behind the words are links to related Wikipedia articles!):
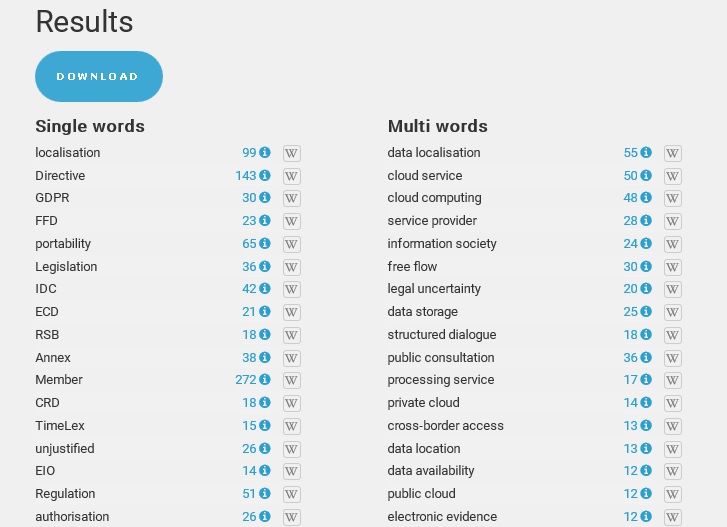
It actually required rather four clicks than OneClick, but the result was worth the effort. There isn’t a lot of “noise” (irrelevant terms) in the term candidate list, one of the reasons that often put me off in the past when I tried to use term extraction tools to prepare for an interpreting assignment. In the meeting where I tested OneClickTerms, at the end the only word I missed in the results was the regulatory scrutiny board. Interestingly, it was also missing from the list I had obtained from a German text on the same subject (Ausschuss für Regulierungskontrolle). But all the other relevant terms that popped up during the meeting were there. And what is more, by quickly scanning the extraction list in my target language, German, I could activate a lot of terminology I would otherwise definitely have had to think about twice while interpreting. So to me it definitely is a very efficient way of reducing the cognitive load in simultaneous interpreting.
The results list can be downloaded as a txt file, but copy & paste into MS Excel, for example, works just as fine, plus it puts both single and multi words into the same column. After unmerging all cells the terms can easily be sorted by frequency, which makes your five-minute emergency preparation almost perfect (as perfect as a five-minute preparation can get, that is).
Furthermore, even if you do have enough time for preparation, extracting and scanning the terminology as a first step may help you to focus on the substance when reading the text afterwards.
There is a free one month trial, after that the service can be subscribed to from 100 EUR/year (or 12.32 EUR/month) plus VAT. It includes many other features, like bilingual corpus building – but that’s a different story.
About the author:
Anja Rütten is a freelance conference interpreter for German (A), Spanish (B), English (C) and French (C) based in Düsseldorf, Germany. She has specialised in knowledge management since the mid-1990s.
Noch fünf Minuten bis zum Konferenzbeginn und ein hundertseitiges pdf zur Vorbereitung schneit (hoffentlich elektronisch) in die Kabine. Was macht man? Klar: Text in eine Maschine werfen, Knopf drücken, Terminologieliste wird ausgespuckt. Damit kann man sich dann zumindest einen groben Überblick verschaffen … Nun, es sieht so aus, als sei dieser Traum tatsächlich wahr geworden!
OneClick Terms von SketchEngine ist ein browser-basiertes (super!) Terminologieextraktionstool, das extrem einfach in der Handhabung ist. Es hat alles, was es braucht, und mehr auch nicht (ebenfalls super!). Upload – Einstellungen – Ergebnisse. Fertig.
Wenn man sich mit seinem kostenlosen Testaccount eingewählt hat, kann man eine Datei im folgenden Format hochladen: tmx, xliff (2.x), pdf, doc(x), html, txt. Die unterstützten Sprachen sind Tschechisch, Deutsch, Englisch, Spanisch, Französisch, Italienisch, Japanisch, Koreanisch, Niederländisch, Polnisch, Portugiesisch, Russisch, Slowakisch, Slowenisch, Chinesisch vereinfacht und Chinesisch traditionell.
Die Einstellungen muss man zuächst einmal gar nicht anfassen. Möchte man es doch, kann man folgende Parameter verändern:
- wie häufig oder selten sollte der extrahierte Terminus sein
- soll das Wort in der (deklinierten oder konjugierten) Form angezeigt werden, in der es im Text vorkommt, oder in seiner Grundform
- wie oft muss ein Termkandidat im Text vorkommen, um es auf die Ergebnisliste zu schaffen
- sollen Zahlen bzw. Zahl-/Buchstabenkombinationen in der Ergebnisliste erscheinen
- wie lang soll die Ergebnisliste sein
Als ich OneClick Terms, getestet habe, bekam ich auf Anhieb äußerst relevante Ergebnisse. Ich habe um 8:55 Uhr einen EU-Text über den freien Verkehr nicht-personenbezogener Daten hochgeladen (pdf, etwa 100 Seiten) und hatte um 8:57 Uhr gleich im Browser das folgende Ergebnis angezeigt (und ja, die kleinen Ws hinter den Wörtern sind Links zu passenden Wikipedia-Artikeln!):
Es waren zwar eher vier Klicks als EinKlick, aber das Ergebnis war die Mühe Wert. Es gab wenig Rauschen (irrelevante Termini) in der Termkandidatenliste, einer der Gründe, die mich bislang davon abgehalten haben, Terminologieextraktion beim Dolmetschen zu nutzen. In der Sitzung, bei der ich OneClickTerms getestet habe, fehlte mir am Ende in der Ergebnisliste nur ein einziger wichtiger Begriff aus der Sitzung, regulatory scrutiny board. Dieser Ausschuss für Regulierungskontrolle fehlte interessanterweise auch in der Extraktionsliste, die ich zum gleichen Thema anhand eines deutschen Textes erstellt hatte. Alle anderen relevanten Termini, die während der Sitzung verwendet wurden, fanden sich aber tatsächlich in der Liste. Und noch dazu hatte ich den Vorteil, dass ich nach kurzem Scannen der Liste auf Deutsch, meiner Zielsprache, sehr viele Terminie schon aktiviert hatte, nach denen die ich ansonsten während des Dolmetschens sicher länger in meinem Gedächtnis hätte kramen müssen. Für mich definitiv ein Beitrag zur kognitiven Entlastung beim Simultandolmetschen.
Die Ergebnisliste kann man als txt-Datei herunterladen, aber Copy & Paste etwa in MS-Excel hinein funktioniert genauso gut. Man hat dann auch gleich die Einwort- und Mehrwort-Termini zusammen in einer Spalte. Wenn man den Zellenverbund aufhebt, kann man danach auch noch die Einträge bequem nach Häufigkeit sortieren. Damit ist die Fünf-Minuten-Notvorbereitung quasi perfekt (so perfekt, wie eine fünfminütige Vorbereitung eben sein kann).
Aber selbst wenn man jede Menge Zeit für die Vorbereitung hat, kann es ganz hilfreich sein, bevor man einen Text liest, die vorkommende Terminologie einmal auf einen Blick gehabt zu haben. Mir zumindest hilft das dabei, mich beim Lesen stärker auf den Inhalt als auf bestimmte Wörter zu konzentrieren.
Man kann OneClick Terms einen Monat lang kostenlos testen, danach gibt es das Abonnement ab 100,00 EUR/Jahr (oder 12,32 EUR/Monat) plus MWSt. Es umfasst noch eine ganze Reihe anderer Funktionen, etwa auch den Aufbau zweisprachiger Korpora – aber das ist dann wieder eine andere Geschichte.
Über die Autorin:
Anja Rütten ist freiberufliche Konferenzdolmetscherin für Deutsch (A), Spanisch (B), Englisch (C) und Französisch (C) in Düsseldorf. Sie widmet sich seit Mitte der 1990er dem Wissensmanagement.
Leave a Reply