Tag: simultaneous interpretation
-

Word Clouds – much nicer than Word Lists
I have been wondering for quite some time if word lists are the best thing I can come up with as a visual support in the booth. They are not exactly appealing to the eye, after all … So I started to play around with word cloud generators a bit to see if they are…
-
Extract Terminology in No Time | OneClick Terms | Ruckzuck Terminologie extrahieren
[for German scroll down] What do you do when you receive 100 pages to read five minutes before the conference starts? Right, you throw the text into a machine and get out a list of technical terms that give you a rough overview of what it’s all about. Now finally, it looks like this dream…
-

Can computers outperform human interpreters?
Unlike many people in the translation industry, I like to imagine that one day computers will be able to interpret simultaneously between two languages just as well as or better than human interpreters do, what with artificial neuronal neurons and neural networks’ pattern-based learning. After all, once hardware capacity allows for it, an artificial neural…
-
How to build one nice multilingual file from several PDFs | Aus zwei (PDFs) mach eins – übersichtliche mehrsprachige PDFs erstellen | Cómo crear un archivo PDF multilingüe
+++ for English see below +++ para español, aun más abajo +++ Wir kennen ihn alle: Den über hundert Seiten langen Geschäftsbericht, vollgepackt mit Grafiken, Tabellen und wertvollen Informationen, und das – Halleluja! – nicht nur im Original, sondern auch noch in 1a-Übersetzung(en) . Einen besseren Fundus für die Dolmetschvorbereitung kann man sich kaum vorstellen.…
-

Digital dementia and conference interpreters – article published in Multilingual July/August 2015
To read this article on effects of digitalisation on conference interpreters’ memory and learning habits, please follow the link to multilingual.com (English only). —————- About the author Anja Rütten is a freelance conference interpreter for German (A), Spanish (B), English (C) and French (C) based in Düsseldorf, Germany. She has specialised in knowledge management…
-

Handschriftlich notieren oder tippen – was sagt die Forschung? | Handwriting vs. typing – what does research tell us?
+++ for English see below +++ Egal, in welchem Kreis von Dolmetschern man darüber redet, geschätzte 10 % schwören immer Stein und Bein, dass sie sich die Dinge besser merken können, wenn sie sie mit Stift und Papier festhalten. Sie pfeifen auch auf die Vorteile des papierlosen Büros, darauf, ihre Unterlagen durchsuchen und Glossare sortieren…
-
Booth-friendly terminology management – Flashterm.eu
+++ for English see below +++ Wer – womöglich auch fürs Übersetzen – eigentlich lieber eine “richtige” Terminologieverwaltung hätte, die obendrein aber noch kabinenfreundlich ist, der sollte einmal bei Flashterm von der Eisenrieth Dokumentations GmbH vorbeischauen. Flashterm basiert auf Filemaker und bietet die Klassiker der Eintragsmöglichkeiten wie Sachgebiete, Synonyme, Kontext usw. , aber auch das…
-
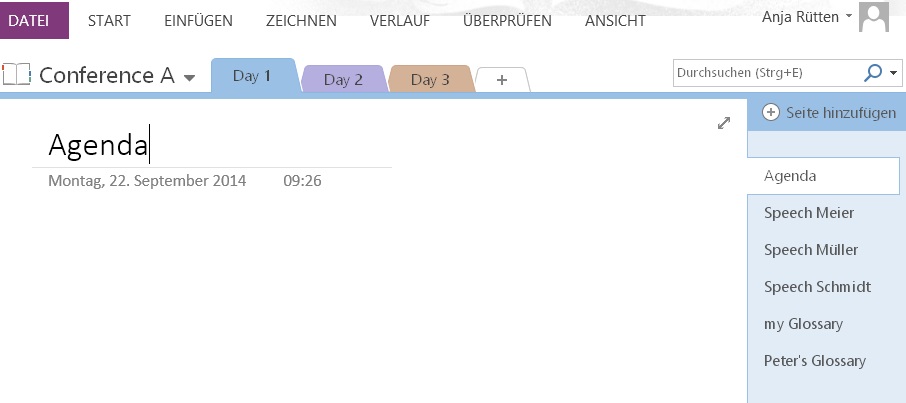
Organise your meeting documents with MS-OneNote – Sitzungsunterlagen perfekt im Zugriff mit Onenote
+++ for English see below +++ Warum scheuen viele Dolmetscher eigentlich davor zurück, völlig papierfrei in die Kabine zu gehen, und wechseln lieber zwischen einem Stapel ausgedruckter Dokumente auf der einen Seite und einem Computer als reine Vokabelsuchmaschine auf der anderen Seite hin und her? Ich vermute, der Grund ist dieser: Man kann einfach nie…
-

Booth-friendly terminology management revisited – 2 newcomers
The nice thing about blogging is that if you miss something out, you are safe to find out within 24 hours. Interestingly, the programs presented in my last article are obviously the “veterans” of terminology management for conference interpreters (most of them have been around for years, since long before tablets and smartphones appeared). Two…
-
Booth-friendly terminology management programs for interpreters – a market snapshot
– This one comes in English, as many non-German-speaking colleagues have asked for it. – This article is meant to give you a very brief overview of the terminology management programs that I am aware of (in alphabetical order), made for simultaneous interpreters. I have tried to highlight the merits and downsides that in my…
-
Mit dem Tablet in die Dolmetschkabine? – The ipad Interpreter von und mit Alex Drechsel
Dass ein Tablet leichter, kleiner und handlicher ist und zudem eine längere Akkulaufzeit hat, sehe ich ein. Ich persönlich trage jedoch lieber 400 g mehr mit mir herum und habe einen richtigen Rechner (= mein komplettes Büro nebst Datenbestand) dabei, der mir überall ein vollwertiges Office-Paket, eine “große” Tastatur und die Möglichkeit bietet, so viele…