Category: Software
-
Airtable.com – a great replacement for Google Sheets | tolle Alternative zu Google Sheets
+++ for English see below +++ Mit der Terminologieverwaltung meiner Träume muss man alles können: Daten teilen, auf allen Geräten nutzen und online wie offline darauf zugreifen (wie mit Interpreters’ Help/Boothmate für Mac oder auch Google Sheets), möglichst unbedenklich Firmenterminologie und Hintergrundinfos des Kunden dort speichern (wie bei Interpreters’ Help), sortieren und filtern (wie in…
-

Dictation Software instead of Term Extraction? | Diktiersoftware als Termextraktion für Dolmetscher?
+++ for English see below +++ Als neulich mein Arzt bei unserem Beratungsgespräch munter seine Gedanken dem Computer diktierte, anstatt zu tippen, kam mir die Frage in den Sinn: “Warum mache ich das eigentlich nicht?” Es folgte eine kurze Fachsimpelei zum Thema Diktierprogramme, und kaum zu Hause, musste ich das natürlich auch gleich ausprobieren. Das…
-
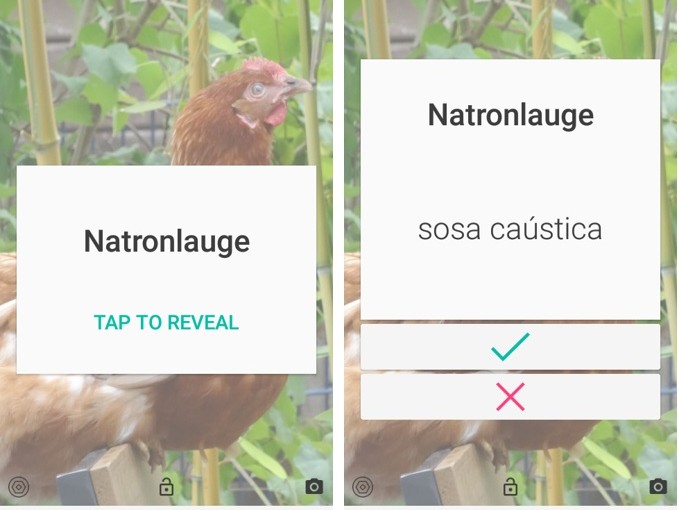
GetSEMPER.com – Charmant-penetranter Vokabeltrainer | Persistant, though charming: your personal vocab trainer
“Aktivierung von Schlüsselterminologie”, “Memor(is)ierung” oder “Vokabelpauken” – egal, wie man es nennt: Eine gewisse Basisausrüstung an Fachterminologie muss einfach ins Hirn. Hierzu kann man sich Listen ausdrucken, Karteikarten schreiben oder eine Reihe von Apps und Programmen nutzen (Anki, Phase 6, Langenscheidt und Pons wurden mir bei einer Spontanumfrage unter Kollegen genannt, auch die InterpretBank bietet…
-
How to build one nice multilingual file from several PDFs | Aus zwei (PDFs) mach eins – übersichtliche mehrsprachige PDFs erstellen | Cómo crear un archivo PDF multilingüe
+++ for English see below +++ para español, aun más abajo +++ Wir kennen ihn alle: Den über hundert Seiten langen Geschäftsbericht, vollgepackt mit Grafiken, Tabellen und wertvollen Informationen, und das – Halleluja! – nicht nur im Original, sondern auch noch in 1a-Übersetzung(en) . Einen besseren Fundus für die Dolmetschvorbereitung kann man sich kaum vorstellen.…
-
Shared glossaries in Google Docs – How to make them work for everyone | Team-Glossare in Google Docs – So wird’s was
+++ for English see below +++ Team-Glossare in Google Docs – So wird’s was Als unsere liebe Kollegin Leonie Wagener 2012 im Rahmen ihrer Masterarbeit eine Erhebung zur vorbereitende Terminologiearbeit unter Konferenzdolmetschern durchführte, gaben 93 % an, zumindest in der Kabine nie ihre Terminologie in Google Docs zu bearbeiten. Mittlerweile ist die gemeinsame Vorbereitung…
-

Booth-friendly terminology management: Intragloss – the missing link between texts and glossaries|die Brücke zwischen Text und Glossar
+++ for English see below +++ Wer schon immer genervt war von der ständigen Wechselei zwischen Redetexten/Präsentationsfolien einerseits und dem Glossar andererseits, der hat jetzt allen Grund zu jubilieren: Dan Kenig und Daniel Pohoryles aus Paris haben mit Intragloss eine Software entwickelt, in der man direkt aus dem Text Termini in sein Glossar befördern kann…
-
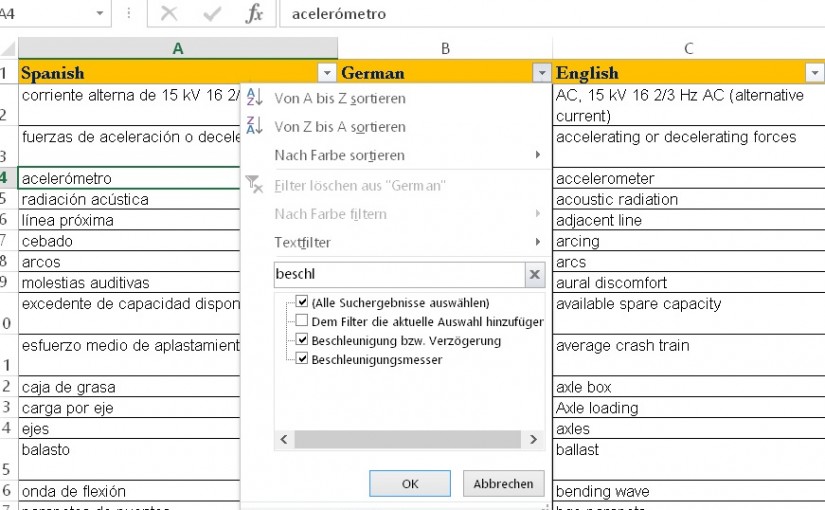
MS-Excel and MS-Access – are they any good for the booth? | Taugen MS-Excel und MS-Access für die Dolmetschkabine?
Es gibt zwar eine ganze Menge Programme, die genau auf die Bedürfnisse von Konferenzdolmetschern zugeschnitten sind (etwa die Schnellsuche in der Kabine oder Strukturen für die effiziente Einsatzvorbereitung), aber eine ganze Reihe von Kollegen setzt dennoch eher auf Feld-Wald-und-Wiesen-Lösungen aus der MS-Office-Kiste. Abgesehen von Word – hier enthalte ich mich jeden Kommentars hinsichtlich dessen Tauglichkeit…
-
Summary table of terminology tools for interpreters | Übersichtstabelle Terminologietools für Dolmetscher | cuadro sinóptico de programas de gestión de terminología para intérpretes
This is an overview of all the terminology management tools for conference interpreters that I am aware of. I will try to keep the information in the table up to date. If there is anything wrong, feel free to post a comment! Dies ist eine Übersicht über alle Terminologieverwaltungstools für Konferenzdolmetscher, die mir bekannt sind.…
-
Booth-friendly terminology management – Flashterm.eu
+++ for English see below +++ Wer – womöglich auch fürs Übersetzen – eigentlich lieber eine “richtige” Terminologieverwaltung hätte, die obendrein aber noch kabinenfreundlich ist, der sollte einmal bei Flashterm von der Eisenrieth Dokumentations GmbH vorbeischauen. Flashterm basiert auf Filemaker und bietet die Klassiker der Eintragsmöglichkeiten wie Sachgebiete, Synonyme, Kontext usw. , aber auch das…
-
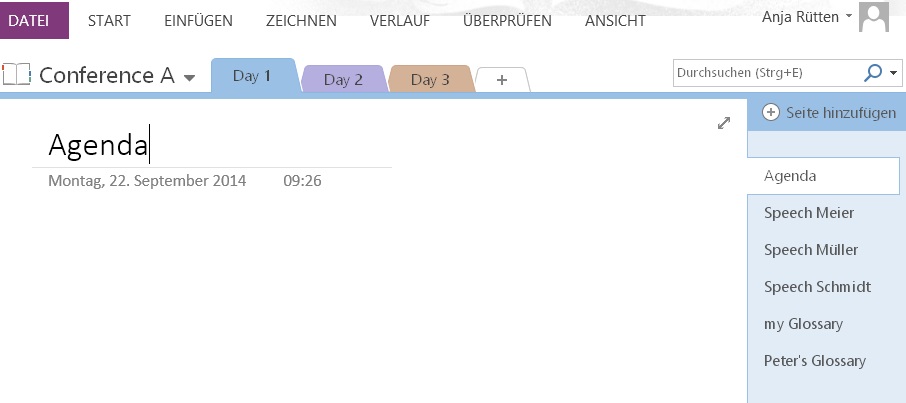
Organise your meeting documents with MS-OneNote – Sitzungsunterlagen perfekt im Zugriff mit Onenote
+++ for English see below +++ Warum scheuen viele Dolmetscher eigentlich davor zurück, völlig papierfrei in die Kabine zu gehen, und wechseln lieber zwischen einem Stapel ausgedruckter Dokumente auf der einen Seite und einem Computer als reine Vokabelsuchmaschine auf der anderen Seite hin und her? Ich vermute, der Grund ist dieser: Man kann einfach nie…
-

Verträge auf dem Smartphone oder Tablet unterschreiben +++ Signing contracts on your smartphone or tablet
+++ For English see below +++ Man kennt es ja: Gerade liegt man unter Palmen, da schneit per Mail der Vertrag für den nächsten Auftrag hinein und will sofort unterschrieben zurückgeschickt werden. Und nun? Zur Rezeption laufen, Vertrag ausdrucken lassen (supervertraulich) und unterschrieben zurückfaxen? Natürlich nicht. Denn zu meiner übergroßen Freude habe ich in meinem…
-

Quick multi-site terminology search | Terminologiesuche in verschiedenen Online-Quellen
For English see below Mal eben bei linguee.com, leo.org, IATE und anderen Nachschlageseiten prüfen, was ein “gillnet” ist und wie man dazu auf Deutsch oder Spanisch sagt, ohne etlichen Webseiten aufrufen und das Wort jedes Mal neu eintippen zu müssen – davon träume ich schon lange. Seit vielen Jahren probiere ich immer wieder Tools dafür…
-

Booth-friendly terminology management revisited – 2 newcomers
The nice thing about blogging is that if you miss something out, you are safe to find out within 24 hours. Interestingly, the programs presented in my last article are obviously the “veterans” of terminology management for conference interpreters (most of them have been around for years, since long before tablets and smartphones appeared). Two…
-
Booth-friendly terminology management programs for interpreters – a market snapshot
– This one comes in English, as many non-German-speaking colleagues have asked for it. – This article is meant to give you a very brief overview of the terminology management programs that I am aware of (in alphabetical order), made for simultaneous interpreters. I have tried to highlight the merits and downsides that in my…
-
Schneller Lesen – dafür gibt es doch bestimmt eine App!
Für eine wirklich bessere Lesetechnik muss man definitiv auch das altmodische Gehirn bemühen, aber einige Aspekte davon – Blickspanne nutzen, nicht im Text zurückspringen – sind ja doch so mechanisch, dass man sich fragt, ob dabei nicht der Computer helfen kann. Und tatsächlich sind auf diese Idee auch schon andere gekommen. Zunächst einmal vielen Dank…
-
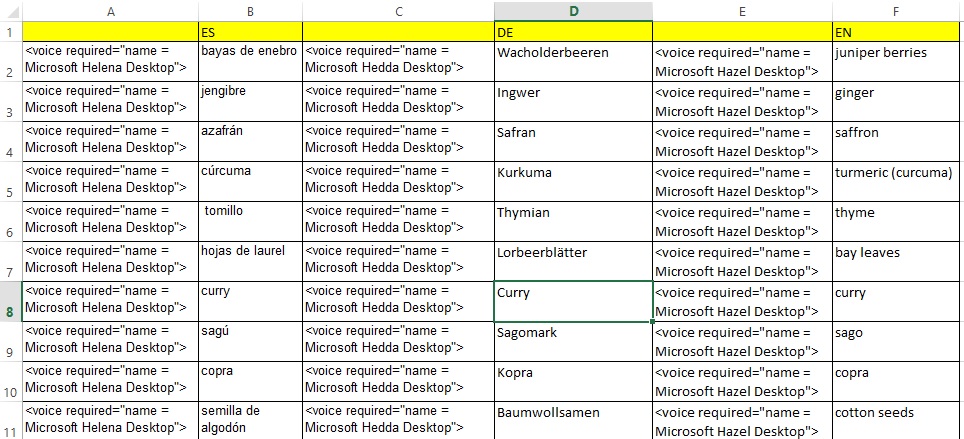
Audio-Vorbereitung 3: Hurra, mein Glossar spricht! Aus mehrsprachigen Tabellen mp3s zaubern
So hocherfreut ich war festzustellen, dass der Computer problemlos geschriebenen Text vorliest und das Vorgelesene auch ohne viel Murren als mp3 herausrückt, so sehr hat es mich dann gefuchst, dass das mit mehrsprachigen Glossaren nicht so mir nichts, dir nichts funktionieren wollte. Ich habe also einige Spracherzeugungssoftware-Hersteller mit der Frage genervt und ein bisschen rumprobiert,…
-
Audio-Vorbereitung 2: Die kostenlosen Microsoft-Computerstimmen und was man damit machen kann
Sich Textdokumente durch eine Computerstimme vorlesen zu lassen, ist einfacher, als mancher vielleicht denkt. Es geht im Prinzip sogar mit den Bordmitteln von Windows 7 oder 8. In diesem Beitrag beschreibe ich im Einzelnen, was man tun muss, damit man sich dann ziemlich komfortabel in MS-Word einen Text vorlesen lassen kann und wie man daraus…