Tag: Spanisch
-
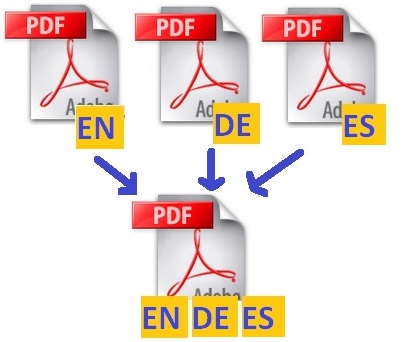
How to build one nice multilingual file from several PDFs | Aus zwei (PDFs) mach eins – übersichtliche mehrsprachige PDFs erstellen | Cómo crear un archivo PDF multilingüe
+++ for English see below +++ para español, aun más abajo +++ Wir kennen ihn alle: Den über hundert Seiten langen Geschäftsbericht, vollgepackt mit Grafiken, Tabellen und wertvollen Informationen, und das – Halleluja! – nicht nur im Original, sondern auch noch in 1a-Übersetzung(en) . Einen besseren Fundus für die Dolmetschvorbereitung kann man sich kaum vorstellen.…
-

Digital dementia and conference interpreters – article published in Multilingual July/August 2015
To read this article on effects of digitalisation on conference interpreters’ memory and learning habits, please follow the link to multilingual.com (English only). —————- About the author Anja Rütten is a freelance conference interpreter for German (A), Spanish (B), English (C) and French (C) based in Düsseldorf, Germany. She has specialised in knowledge management…
-
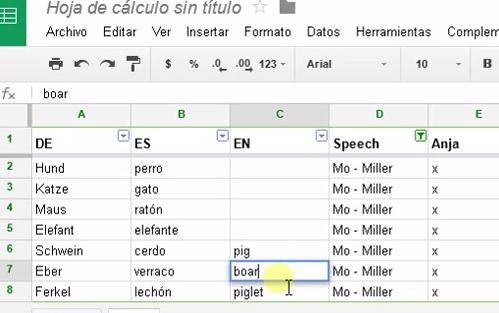
Shared glossaries in Google Docs – How to make them work for everyone | Team-Glossare in Google Docs – So wird’s was
+++ for English see below +++ Team-Glossare in Google Docs – So wird’s was Als unsere liebe Kollegin Leonie Wagener 2012 im Rahmen ihrer Masterarbeit eine Erhebung zur vorbereitende Terminologiearbeit unter Konferenzdolmetschern durchführte, gaben 93 % an, zumindest in der Kabine nie ihre Terminologie in Google Docs zu bearbeiten. Mittlerweile ist die gemeinsame Vorbereitung…
-
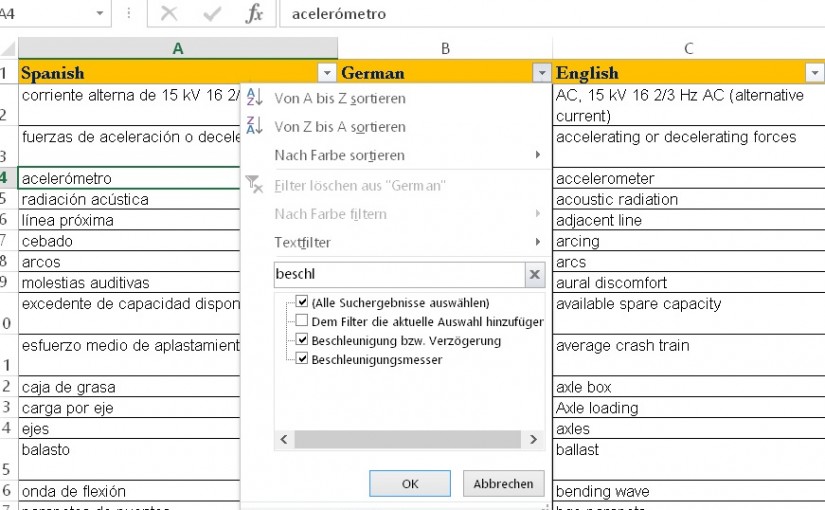
MS-Excel and MS-Access – are they any good for the booth? | Taugen MS-Excel und MS-Access für die Dolmetschkabine?
Es gibt zwar eine ganze Menge Programme, die genau auf die Bedürfnisse von Konferenzdolmetschern zugeschnitten sind (etwa die Schnellsuche in der Kabine oder Strukturen für die effiziente Einsatzvorbereitung), aber eine ganze Reihe von Kollegen setzt dennoch eher auf Feld-Wald-und-Wiesen-Lösungen aus der MS-Office-Kiste. Abgesehen von Word – hier enthalte ich mich jeden Kommentars hinsichtlich dessen Tauglichkeit…
-
Summary table of terminology tools for interpreters | Übersichtstabelle Terminologietools für Dolmetscher | cuadro sinóptico de programas de gestión de terminología para intérpretes
This is an overview of all the terminology management tools for conference interpreters that I am aware of. I will try to keep the information in the table up to date. If there is anything wrong, feel free to post a comment! Dies ist eine Übersicht über alle Terminologieverwaltungstools für Konferenzdolmetscher, die mir bekannt sind.…
-

Handschriftlich notieren oder tippen – was sagt die Forschung? | Handwriting vs. typing – what does research tell us?
+++ for English see below +++ Egal, in welchem Kreis von Dolmetschern man darüber redet, geschätzte 10 % schwören immer Stein und Bein, dass sie sich die Dinge besser merken können, wenn sie sie mit Stift und Papier festhalten. Sie pfeifen auch auf die Vorteile des papierlosen Büros, darauf, ihre Unterlagen durchsuchen und Glossare sortieren…
-
Booth-friendly terminology management – Flashterm.eu
+++ for English see below +++ Wer – womöglich auch fürs Übersetzen – eigentlich lieber eine “richtige” Terminologieverwaltung hätte, die obendrein aber noch kabinenfreundlich ist, der sollte einmal bei Flashterm von der Eisenrieth Dokumentations GmbH vorbeischauen. Flashterm basiert auf Filemaker und bietet die Klassiker der Eintragsmöglichkeiten wie Sachgebiete, Synonyme, Kontext usw. , aber auch das…
-
Mein Gehirn beim Simultandolmetschen| My brain interpreting simultaneously
+++ for English, see below +++ Für gewöhnlich fragen wir uns ja eher, was gerade um Himmels Willen im Kopf des Redners vorgeht, den wir gerade dolmetschen. Unsere Kollegin Eliza Kalderon jedoch stellt in ihrer Doktorarbeit die umgekehrte Frage: Was geht eigentlich in den Dolmetscherköpfen beim Simultandolmetschen vor? Zu diesem Zweck steckt sie Probanden in…
-

Not-To-Do Lists and Not-To-Learn Words
+++ For English see below +++ To-Do-Listen sind eine feine Sache: Einmal aufgeschrieben, kann man lästige Aufgaben zumindest zeitweilig des Gedächtnisses verweisen, und überhaupt ist man viel organisierter und effizienter. Ich zumindest gieße seit Ewigkeiten alles, was nicht bei drei auf den Bäumen ist, in eine Excel-Tabelle – seien es nun Geld, Arbeit, Adressbuch oder…
-

Do interpreters suffer from decision fatigue? – Entscheidungsmüdigkeit beim Dolmetschen?
+++ for English see below +++ Entscheidungen sind anstrengend. Chicken or Pasta, Sekt oder Selters, Windows oder Mac, vom Blatt dolmetschen oder frei – den ganzen Tag müssen wir uns entscheiden, und je mehr Entscheidungen sich aneinander reihen, desto entscheidungsmüder werden wir, desto weniger gründlich wägen wir die Möglichkeiten also ab oder bleiben im Zweifel…
-

Quick multi-site terminology search | Terminologiesuche in verschiedenen Online-Quellen
For English see below Mal eben bei linguee.com, leo.org, IATE und anderen Nachschlageseiten prüfen, was ein “gillnet” ist und wie man dazu auf Deutsch oder Spanisch sagt, ohne etlichen Webseiten aufrufen und das Wort jedes Mal neu eintippen zu müssen – davon träume ich schon lange. Seit vielen Jahren probiere ich immer wieder Tools dafür…
-

Booth-friendly terminology management revisited – 2 newcomers
The nice thing about blogging is that if you miss something out, you are safe to find out within 24 hours. Interestingly, the programs presented in my last article are obviously the “veterans” of terminology management for conference interpreters (most of them have been around for years, since long before tablets and smartphones appeared). Two…
-
Booth-friendly terminology management programs for interpreters – a market snapshot
– This one comes in English, as many non-German-speaking colleagues have asked for it. – This article is meant to give you a very brief overview of the terminology management programs that I am aware of (in alphabetical order), made for simultaneous interpreters. I have tried to highlight the merits and downsides that in my…
-
Schneller Lesen – dafür gibt es doch bestimmt eine App!
Für eine wirklich bessere Lesetechnik muss man definitiv auch das altmodische Gehirn bemühen, aber einige Aspekte davon – Blickspanne nutzen, nicht im Text zurückspringen – sind ja doch so mechanisch, dass man sich fragt, ob dabei nicht der Computer helfen kann. Und tatsächlich sind auf diese Idee auch schon andere gekommen. Zunächst einmal vielen Dank…
-
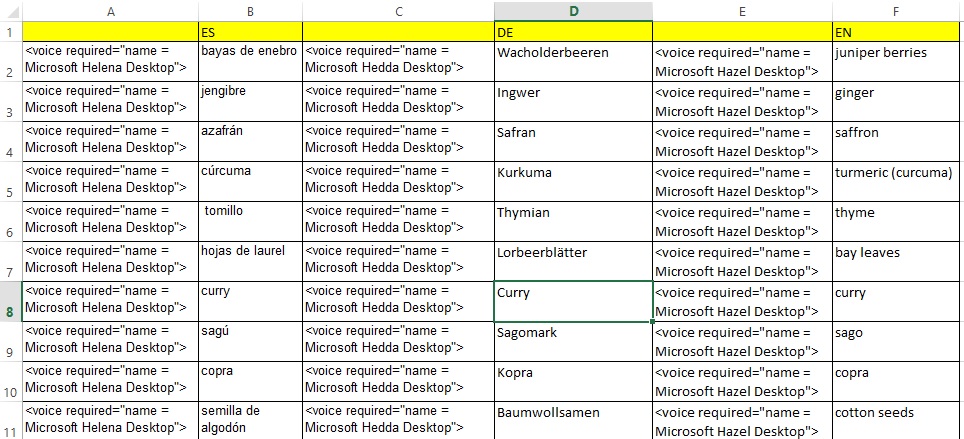
Audio-Vorbereitung 3: Hurra, mein Glossar spricht! Aus mehrsprachigen Tabellen mp3s zaubern
So hocherfreut ich war festzustellen, dass der Computer problemlos geschriebenen Text vorliest und das Vorgelesene auch ohne viel Murren als mp3 herausrückt, so sehr hat es mich dann gefuchst, dass das mit mehrsprachigen Glossaren nicht so mir nichts, dir nichts funktionieren wollte. Ich habe also einige Spracherzeugungssoftware-Hersteller mit der Frage genervt und ein bisschen rumprobiert,…
-
Audio-Vorbereitung 1 oder: Liest mir mal bitte jemand meine Vorbereitungstexte vor?
Als Dolmetscher sind wir ja alle auch ein bisschen in den Charme der gesprochenen Sprache verliebt. Meine Frage, wie ich auch in der Dolmetschvorbereitung mehr mit gesprochenen statt geschriebenen Wörtern zu tun haben könnte, hat deshalb zwar auch zum Ziel, beispielsweise die Autofahrt zum Anhören von Texten oder auch von mehrsprachiger Terminologie zu nutzen (mobile…