Tag: terminology management
-

The new IATE interpreters’ view – what’s in it for EU meeting preparation?
The EU’s terminology database has been around for quite some time – the project was launched back in 1999 and has been available to the public since 2007. Recently, it has been revamped, and an “interpreters’ view” has been added. All EU interpreters, staff and freelancers alike, have access to it, and it is tailored…
-
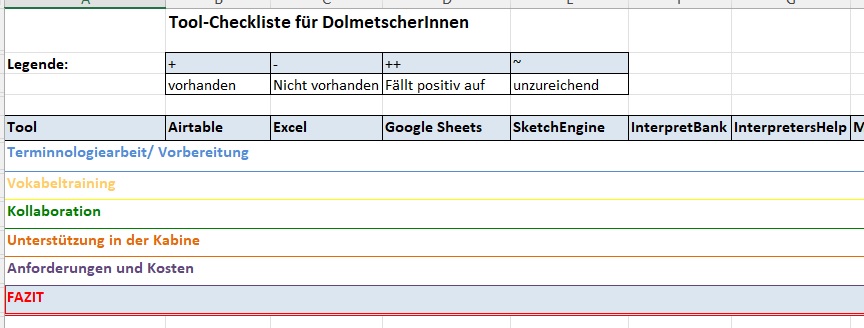
Checklist table of useful terminology tools for interpreters
Do you sometimes wonder which tools best serve your purpose as a conference interpreter? Well, two of my pollitos did, and they came up with this very handy and detailed checklist. It shows all sorts of terminology, spreadsheet, and extraction tools with their pros and cons. Thanks a lot to Eliana Cajas Balcazar y Vanessa…
-

About Term Extraction, Guesswork and Backronyms – Impressions from JIAMCATT 2018 in Geneva
JIAMCATT is the International Annual Meeting on Computer-Assisted Translation and Terminology, a IAMLAP taskforce where most international organizations, various national institutions and academic bodies exchange information and experience in the field of terminology and translation. For this year’s JIAMCATT edition in Geneva, I had the honour of running a workshop on Tools for Interpreters –…
-

InterpretBank 4 review
InterpretBank by Claudio Fantinuoli, one of the pioneers of terminology tools for conference interpreters (or CAI tools), already before the new release was full to the brim with useful functions and settings that hardly any other tool offers. It was already presented in one of the first articles of this blog, back in 2014. So now…
-

Booth notes wanted for a study | Kabinenzettel für Studienzwecke gesucht
Dear fellow conference interpreters! For a study on information management in the booth, I am currently collecting sample booth notes (those papers you scribble terminology, names, numbers, acronyms or whatever on). So if you would like to make your personal contribution to this study, it would be great if you could email or whatsapp me…
-

Impressions from Translating and the Computer 38
The 38th ‘Translating and the Computer’ conference in London has just finished, and, as always, I take home a lot of inspiration. Here are my personal highlights: Sketch Engine, a language corpus management and query system, offers loads of useful functions for conference preparation, like web-based (actually Bing-based) corpus-building, term extraction (the extraction results come…
-
Hello from the other side – Chinese and Terminology Tools. A guest article by Felix Brender 王哲謙
As Mandarin Chinese interpreters, we understand that we are somewhat rare beings. After all, we work with a language which, despite being a UN language, is not one you’d encounter regularly. We wouldn’t expect colleagues working with other, more frequently used languages to know about the peculiarities of Mandarin. This applies not least to terminology…
-
Booth-friendly terminology management: Glossarmanager.de
Believe it or not, only a few weeks ago I came across just another booth-friendly terminology management program (or rather it was kindly brought to my attention by a student when I talked about the subject at Heidelberg University). It has been around since 2008 and completely escaped my attention. So I am all the…
-
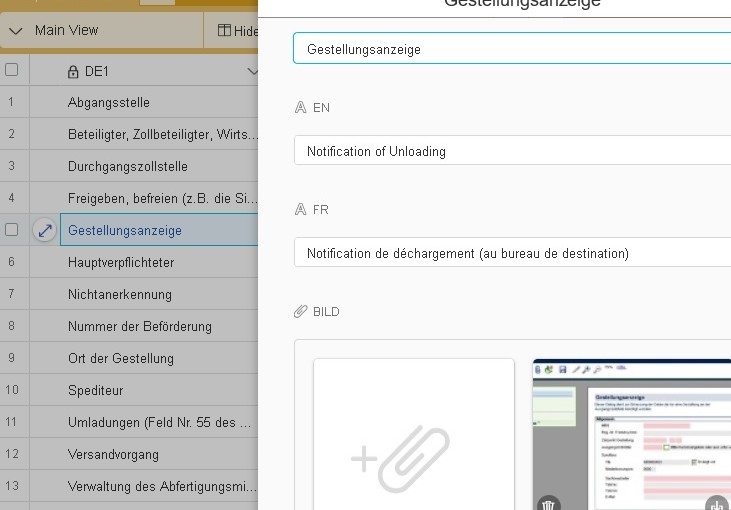
Airtable.com – a great replacement for Google Sheets | tolle Alternative zu Google Sheets
+++ for English see below +++ Mit der Terminologieverwaltung meiner Träume muss man alles können: Daten teilen, auf allen Geräten nutzen und online wie offline darauf zugreifen (wie mit Interpreters’ Help/Boothmate für Mac oder auch Google Sheets), möglichst unbedenklich Firmenterminologie und Hintergrundinfos des Kunden dort speichern (wie bei Interpreters’ Help), sortieren und filtern (wie in…
-

Zu Gast in Brüssel bei “Radio Alex”, auch bekannt als #LangFM
Diesen Monat war ich gemeinsam mit Leonie Wagener zu Gast in Brüssel an Alex Drechsel’s Podcast-Küchentisch. Sehr nett war’s – hier könnt Ihr reinhören: http://www.adrechsel.de/langfm/terminologie +++ Seminarankündigung +++ Wer beim Hören Appetit auf mehr Wissens- oder Terminologiemanagement bekommt und vom Rheinland nicht allzu weit entfernt ist (oder den Weg dorthin nicht scheut), könnte vielleicht Spaß…
-

Booth-friendly terminology management: Intragloss – the missing link between texts and glossaries|die Brücke zwischen Text und Glossar
+++ for English see below +++ Wer schon immer genervt war von der ständigen Wechselei zwischen Redetexten/Präsentationsfolien einerseits und dem Glossar andererseits, der hat jetzt allen Grund zu jubilieren: Dan Kenig und Daniel Pohoryles aus Paris haben mit Intragloss eine Software entwickelt, in der man direkt aus dem Text Termini in sein Glossar befördern kann…
-
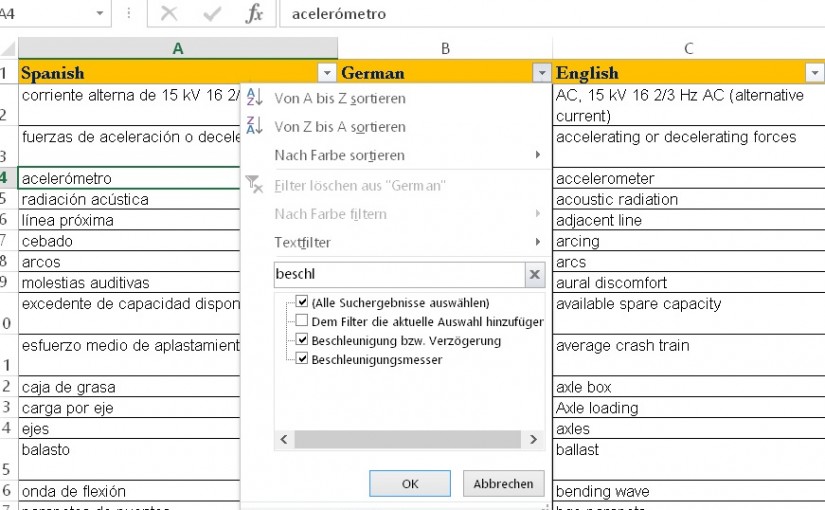
MS-Excel and MS-Access – are they any good for the booth? | Taugen MS-Excel und MS-Access für die Dolmetschkabine?
Es gibt zwar eine ganze Menge Programme, die genau auf die Bedürfnisse von Konferenzdolmetschern zugeschnitten sind (etwa die Schnellsuche in der Kabine oder Strukturen für die effiziente Einsatzvorbereitung), aber eine ganze Reihe von Kollegen setzt dennoch eher auf Feld-Wald-und-Wiesen-Lösungen aus der MS-Office-Kiste. Abgesehen von Word – hier enthalte ich mich jeden Kommentars hinsichtlich dessen Tauglichkeit…
-
Summary table of terminology tools for interpreters | Übersichtstabelle Terminologietools für Dolmetscher | cuadro sinóptico de programas de gestión de terminología para intérpretes
This is an overview of all the terminology management tools for conference interpreters that I am aware of. I will try to keep the information in the table up to date. If there is anything wrong, feel free to post a comment! Dies ist eine Übersicht über alle Terminologieverwaltungstools für Konferenzdolmetscher, die mir bekannt sind.…
-
Booth-friendly terminology management – Flashterm.eu
+++ for English see below +++ Wer – womöglich auch fürs Übersetzen – eigentlich lieber eine “richtige” Terminologieverwaltung hätte, die obendrein aber noch kabinenfreundlich ist, der sollte einmal bei Flashterm von der Eisenrieth Dokumentations GmbH vorbeischauen. Flashterm basiert auf Filemaker und bietet die Klassiker der Eintragsmöglichkeiten wie Sachgebiete, Synonyme, Kontext usw. , aber auch das…
-

Not-To-Do Lists and Not-To-Learn Words
+++ For English see below +++ To-Do-Listen sind eine feine Sache: Einmal aufgeschrieben, kann man lästige Aufgaben zumindest zeitweilig des Gedächtnisses verweisen, und überhaupt ist man viel organisierter und effizienter. Ich zumindest gieße seit Ewigkeiten alles, was nicht bei drei auf den Bäumen ist, in eine Excel-Tabelle – seien es nun Geld, Arbeit, Adressbuch oder…
-

Quick multi-site terminology search | Terminologiesuche in verschiedenen Online-Quellen
For English see below Mal eben bei linguee.com, leo.org, IATE und anderen Nachschlageseiten prüfen, was ein “gillnet” ist und wie man dazu auf Deutsch oder Spanisch sagt, ohne etlichen Webseiten aufrufen und das Wort jedes Mal neu eintippen zu müssen – davon träume ich schon lange. Seit vielen Jahren probiere ich immer wieder Tools dafür…
-

Booth-friendly terminology management revisited – 2 newcomers
The nice thing about blogging is that if you miss something out, you are safe to find out within 24 hours. Interestingly, the programs presented in my last article are obviously the “veterans” of terminology management for conference interpreters (most of them have been around for years, since long before tablets and smartphones appeared). Two…
-
Booth-friendly terminology management programs for interpreters – a market snapshot
– This one comes in English, as many non-German-speaking colleagues have asked for it. – This article is meant to give you a very brief overview of the terminology management programs that I am aware of (in alphabetical order), made for simultaneous interpreters. I have tried to highlight the merits and downsides that in my…