Category: Hören | Listening | Escucha
-
Distance interpreting – AIIC’s guidelines in practice | a guest article by Mathilde Kuhn
As I was looking for a subject for my master’s thesis, I read in many articles and books that remote simultaneous interpreting (RSI) is not very popular amongst interpreters. It comes with multiple difficulties: communication with a boothmate is harder, internet connections can be unstable, lack of social contact, health risks, etc. To mitigate the…
-

AI-made podcasts by NotebookLM and Jellypod
AI generated podcasts – are they any good for meeting preparation, or for conference interpreter training? My student Rebecca Bremer, a real podcast aficionado, wanted to find out and did some testing. Here’s what she has found out: Guest article by Rebecca Bremer, student of conference interpreting at TH Köln General considerations Podcasts have become…
-
Live transcription in RSI with Otter.ai and Airgram.io
Yesterday, in a Remote Simultaneous Interpreting team with colleagues being distributed all over Europe, it suddenly occurred to us to play around a bit with live transcription as a support (thanks to Mike Morandin’s innocent question if anyone had ever used it). No sooner said than done – within a few minutes our wonderful chef…
-

Will 3D audio make remote simultaneous interpreting a pleasure?
Now THAT’S what I want: Virtual Reality for my ears! Apparently, simultaneous interpreters are not the only ones suffering from Zoom fatigue, i.e. the confusion and inability to physically locate a speaker using our ears can lead to a condition that’s sometimes referred to as “Zoom Fatigue”. But it looks like there is still reason…
-

Why not listen to football commentary in several languages? | Fußballspiele mehrsprachig verfolgen
+++ for English, see below +++ para español, aún más abajo +++ Ich weiß nicht, wie es Euch ergeht, aber wenn ich im Fernsehen ein Fußballspiel verfolge, frage ich mich mitunter, was jetzt wohl der Kommentator der anderen Mannschaft bzw. Nationalität dazu gerade sagt. Die Idee, (alternative) Fußballkommentare über das Internet zu streamen, hat sich…
-
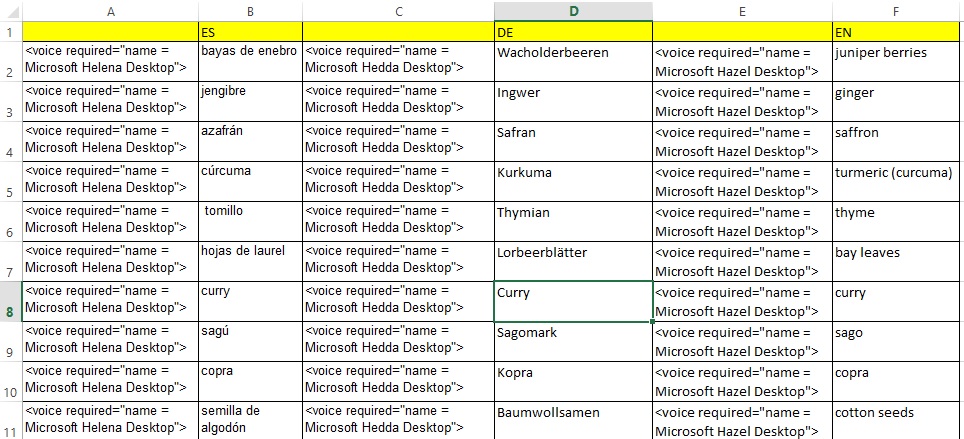
Audio-Vorbereitung 3: Hurra, mein Glossar spricht! Aus mehrsprachigen Tabellen mp3s zaubern
So hocherfreut ich war festzustellen, dass der Computer problemlos geschriebenen Text vorliest und das Vorgelesene auch ohne viel Murren als mp3 herausrückt, so sehr hat es mich dann gefuchst, dass das mit mehrsprachigen Glossaren nicht so mir nichts, dir nichts funktionieren wollte. Ich habe also einige Spracherzeugungssoftware-Hersteller mit der Frage genervt und ein bisschen rumprobiert,…
-
Audio-Vorbereitung 2: Die kostenlosen Microsoft-Computerstimmen und was man damit machen kann
Sich Textdokumente durch eine Computerstimme vorlesen zu lassen, ist einfacher, als mancher vielleicht denkt. Es geht im Prinzip sogar mit den Bordmitteln von Windows 7 oder 8. In diesem Beitrag beschreibe ich im Einzelnen, was man tun muss, damit man sich dann ziemlich komfortabel in MS-Word einen Text vorlesen lassen kann und wie man daraus…
-
Audio-Vorbereitung 1 oder: Liest mir mal bitte jemand meine Vorbereitungstexte vor?
Als Dolmetscher sind wir ja alle auch ein bisschen in den Charme der gesprochenen Sprache verliebt. Meine Frage, wie ich auch in der Dolmetschvorbereitung mehr mit gesprochenen statt geschriebenen Wörtern zu tun haben könnte, hat deshalb zwar auch zum Ziel, beispielsweise die Autofahrt zum Anhören von Texten oder auch von mehrsprachiger Terminologie zu nutzen (mobile…