Tag: conference interpreters
-

10 or so books every conference interpreter should read
I was told that bucket lists are key to successful blogging – so here is mine. 10 or so books every conference interpreter should read: The Bible (in all your working languages) Maschinenelemente für Dummies (machine parts for dummies) Chemie Kompaktwissen iIntroduction to chemistry) The Times Complete History of the World International Financial Reporting Standards…
-
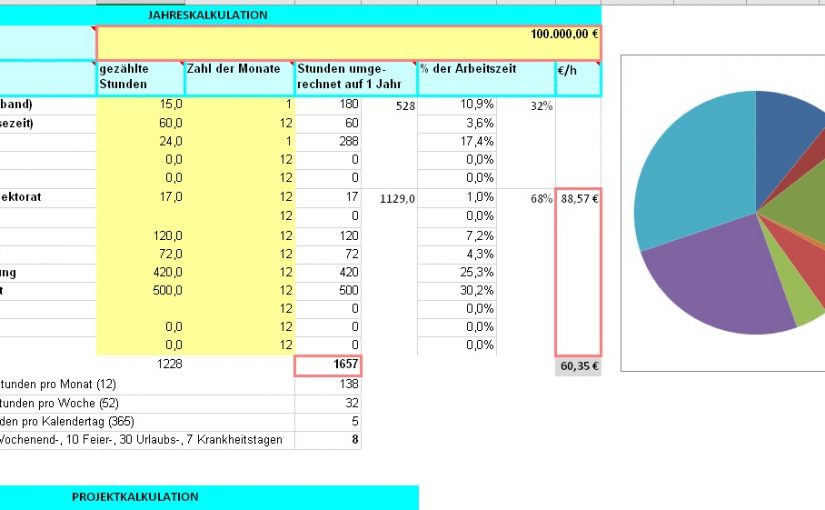
Honorarkalkulator für Dolmetscher – Excel-Datei und Video Tutorials aus #aiicDfD2018
“Grundhonorare, Projekthonorare, Vorbereitungshonorare – nicht immer funktionieren Tagessätze” – laut Inés de Chavarría (der ein megagroßes Dankeschön für die Orga gebührt!) eine zentrale Erkenntnis aus den Diskussionen des AIIC-Workshops Dolmetscher für Dolmetscher 2018 in Stuttgart. In diesem Sinne nun also ran ans Kalkulieren! Hier zum Ansehen in Google Sheets oder zum Herunterladen im Excel-Format der…
-
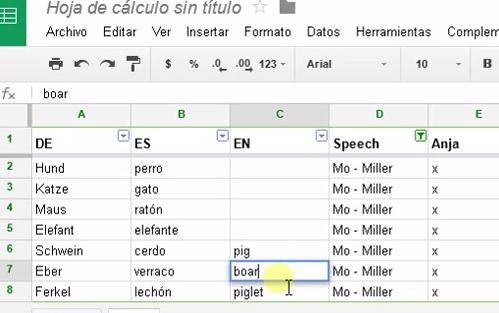
Shared glossaries in Google Docs – How to make them work for everyone | Team-Glossare in Google Docs – So wird’s was
+++ for English see below +++ Team-Glossare in Google Docs – So wird’s was Als unsere liebe Kollegin Leonie Wagener 2012 im Rahmen ihrer Masterarbeit eine Erhebung zur vorbereitende Terminologiearbeit unter Konferenzdolmetschern durchführte, gaben 93 % an, zumindest in der Kabine nie ihre Terminologie in Google Docs zu bearbeiten. Mittlerweile ist die gemeinsame Vorbereitung…