Category: machine translation
-
Fast but awkward vs. well thought-out but slow – Comparing machine translation to human translation | guest article by Luca Etzold
AI and with it MT has been gaining more and more traction in the language industry. However, human translators have not gone extinct just yet, and there are good reasons for it, some of which I explored as part of my Master’s thesis. In it, I translated a podcast interview from English to German and…
-
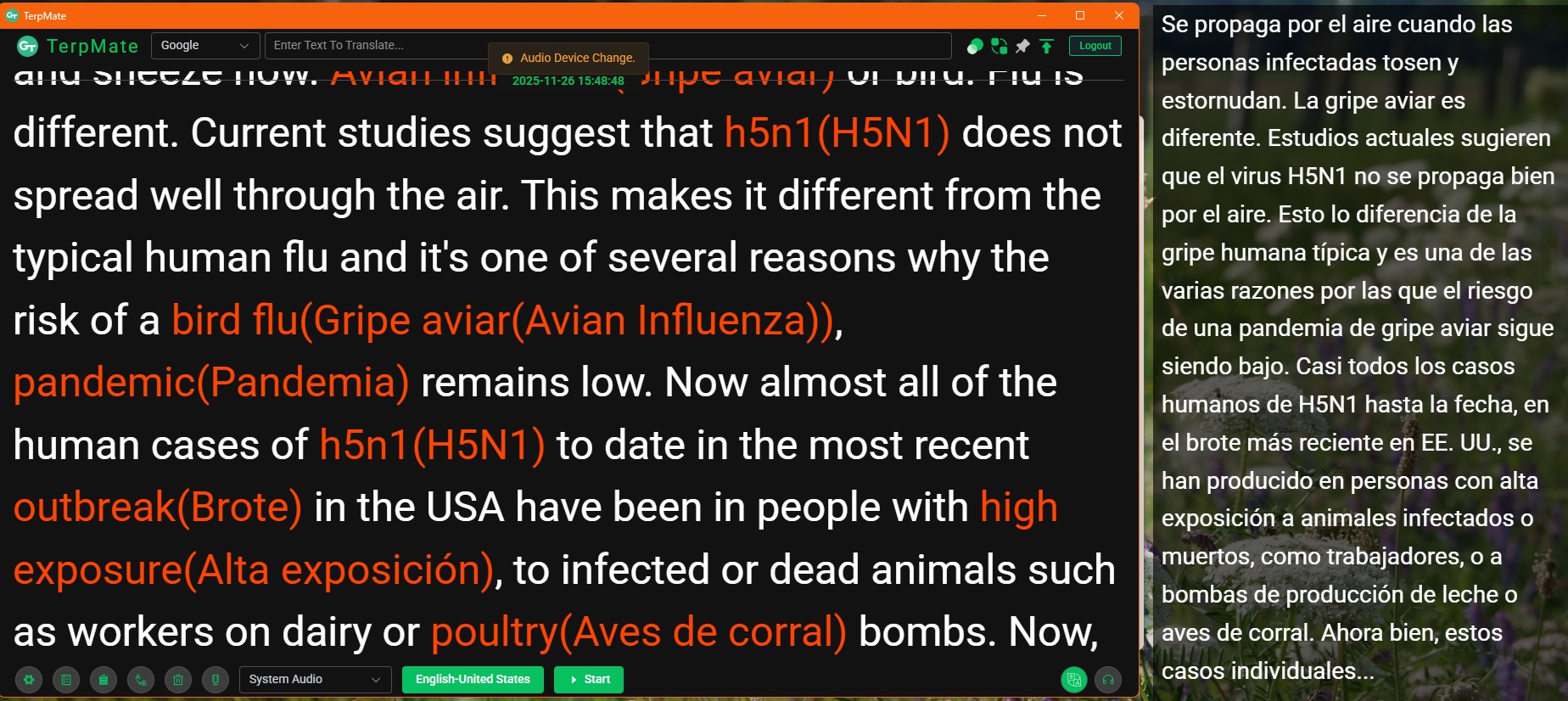
TerpMate – the (second) newest kid on the block of CAI tools
TerpMate was published in April this year (2025). It was the latest addition to the CAI tool landscape indeed, just until SightTerp was released last month (review coming soon). Now, TerpMate is part of the Greenterp ecosystem created by Green Terp Technologies Pte Ltd and their CEO Bernhard Song, who himself is a professional conference…
-

Lara Translate – offering faithful, fluid, or creative machine translation
When a spoken text is being interpreted, the target text is often less attached to the morpho-syntactical structures of the source text than that of a written translation. Complex sentences are disentangled, so that they are easier to process and represent less of a cognitive load both to interpreters and to listeners, redundancies are smoothed…
-

Testing Cymo Note
Testing software in a group of tech-crazy interpreters is so much more entertaining and insightful than just playing around on my own. AIIC’s AI workstream (link to LinkedIn profile) recently embarked on its first team testing session, and we chose Cymo Note as our first subject of interest. Cymo offers a whole range of support…
-

Eight rules to get the most out of live translation apps
This month at the Technical University of Cologne we took a closer look at some live translation apps, in particular Galaxy’s live translation app for phone calls. Prof. Ralph Krüger and I, together with journalist Steffen Berner, wanted to find out how useful they are. It was both an interesting and entertaining experience. Obviously, nothing…
-

Nachlese zum Runden Tisch des VKD im BDÜ zum Thema Künstliche Intelligenz
Artikel aus dem VKD-Kurier Dezember 2023 [English version here] Quo vadis denn jetzt schon wieder? Am 17. Oktober 2023 lud der VKD zum virtuellen Runden Tisch in Sachen KI ein. Mir wurde die Ehre zuteil, ein Impulsreferat halten zu dürfen – für meine Begriffe eine zweifelhafte Ehre, weil in meinem Kopf über allen Fragen rund…
-
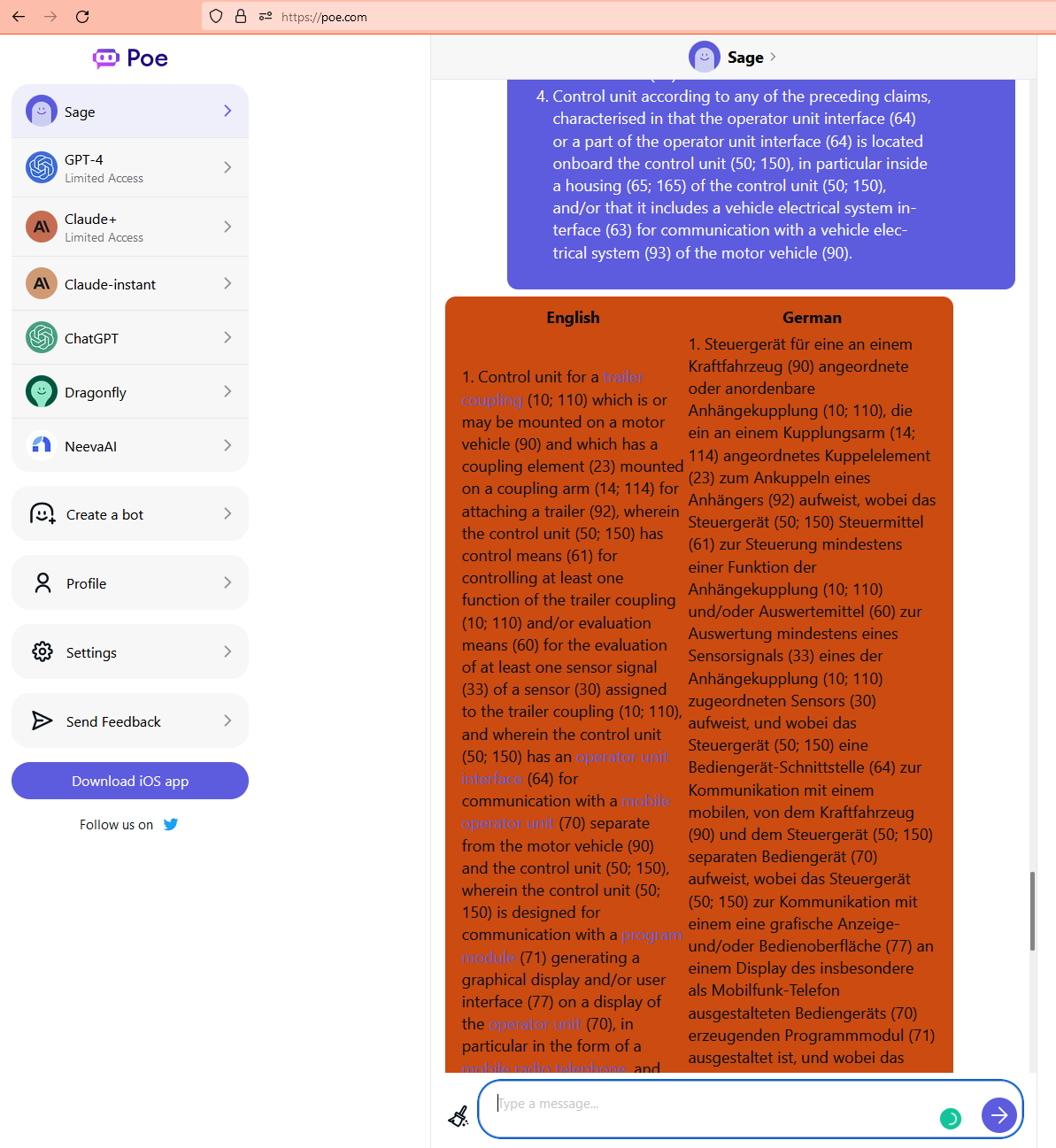
How to tell a chatbot like ChatGPT or Sage to align texts in different languages in a table (and besides get a summary )
If you have the same text in several languages and you want the different versions neatly arranged in a table with the sentences in the different language versions next to each other, a chatbot like ChatGPT may be able to help. Especially when texts come in pdf format, just copying and pasting them can already…
-
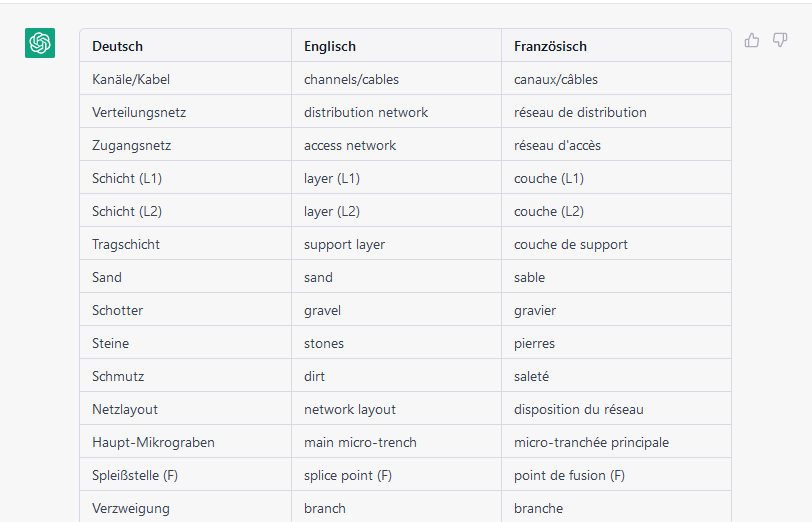
How to tell ChatGPT to extract terminology from parallel texts in different languages
My dear colleague (and former student) Florian Pfaffelhuber just drew my attention to the fact that ChatGPT is great at multilingual terminology extraction. It can also handle more than two languages and will create very nice multilingual glossary tables for you. What worked best when we tested it today was to copy the prompt and…
-

Use ChatGPT, DeepL & Co. to boost your conference preparation
In this article I would like to show you how I like to use DeepL, Google Translate, Microsoft Translator, and ChatGPT as a conference interpreter, especially in conference preparation. You will also see how to use GT4T to combine the different options. I did some testing for this year’s Innovation in Interpreting Summit and I…
-

Automatic bilingual term extraction with OneClickTerms by SketchEngine
When I wrote about this great terminology extraction tool OneClickTerms back in 2017 I was already quite enthusiastic about how useful it was for last-minute conference preparation. But the one thing I didn’t mention back then (or maybe it wasn’t available yet) was that OneClickTerms does not only extract terminology from monolingual documents, but it…
-
Here comes my first-AI written blog post
I was feeling a bit lazy today, so I thought I might give Artificial Intelligence a try. And here we go, this is my first blog post written by an AI writing assistant: How to Use the Best Interpreting Technology Translation and interpreting services are crucial for business success. If you’re a business owner, it…
-
Natural Language Processing – What’s in it for interpreters?
“Natural Language Processing? Hey, that’s what I do for a living!” That’s what I thought when I heard about the live talk “A Glimpse at the Future of NLP” (big thank you to Julia Böhm for pointing this out to me). As I am always curious about what happens in AI and language processing, I…
-

DeepL – not too bad, even if it turns marriage into war
After Microsoft Translate and Google Translate, last week I decided to take a closer look at DeepL‘s beta desktop application. I had to prepare over 50 Power Point slides filled with text about quite a number of rulings of the European Court of Justice. I was pretty sure these would be read out at high…
-
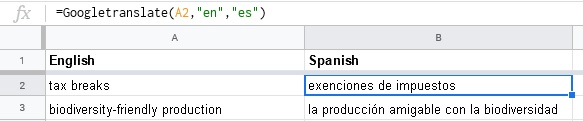
How to Build Your Self-Translating Glossary in Google Sheets
I am certainly not saying that Google can create your glossaries for you when preparing for a technical conference on African wildlife or nanotubes. But if you know your languages well enough to tell a bad translation from a good one, it may still be a time-saver. Especially for those words you don’t use every…