[Dolmetscher wissen alles] Interpreters know everything
A blog on knowledge & conference interpreting
-
Paperless Preparation at International Organisations – an Interview with Maha El-Metwally
Maha El-Metwally has recently written a master’s thesis at the University of Geneva on preparation for conferences of international organisations using tablets. She is a freelance conference interpreter for Arabic A, English B, French and Dutch C domiciled in Birmingham. How come you know so much about the current preparation practice of conference interpreters at so…
-

InterpretBank 4 review
InterpretBank by Claudio Fantinuoli, one of the pioneers of terminology tools for conference interpreters (or CAI tools), already before the new release was full to the brim with useful functions and settings that hardly any other tool offers. It was already presented in one of the first articles of this blog, back in 2014. So now…
-

Zeit sparen bei der Videovorbereitung | How to save time when preparing video speeches
Videos als Vorbereitungsmaterial für eine Konferenz haben unzählige Vorteile. Der einzige Nachteil: Sie sind ein Zeitfresser. Man kann nicht wie bei einem schriftlichen Text das Ganze überfliegen und wichtige Stellen vertiefen, markieren und hineinkritzeln. Zum Glück hat Alex Drechsel sich in einem Blogbeitrag dazu Gedanken gemacht und ein paar Tools ausgegraben, die dem Elend ein…
-

Booth notes wanted for a study | Kabinenzettel für Studienzwecke gesucht
Dear fellow conference interpreters! For a study on information management in the booth, I am currently collecting sample booth notes (those papers you scribble terminology, names, numbers, acronyms or whatever on). So if you would like to make your personal contribution to this study, it would be great if you could email or whatsapp me…
-

Can computers outperform human interpreters?
Unlike many people in the translation industry, I like to imagine that one day computers will be able to interpret simultaneously between two languages just as well as or better than human interpreters do, what with artificial neuronal neurons and neural networks’ pattern-based learning. After all, once hardware capacity allows for it, an artificial neural…
-

Wissensmanagement im Konferenzdolmetschen – ein bisschen Theorie
Was bedeutet eigentlich Wissensmanagement für Konferenzdolmetscher? Was man für einen Dolmetscheinsatz wissen muss, ist schnell beschrieben: So ziemlich alles in allen Arbeitssprachen. Auf der Händlertagung eines Waschmaschinenherstellers kann es plötzlich um Fußballtaktik gehen, der CFO bei einer Bilanzpressekonferenz hat womöglich eine Schwäche für Bibelzitate. Deshalb gilt grundsätzlich: Die Vorbereitung ist nie zu Ende. Da aber…
-
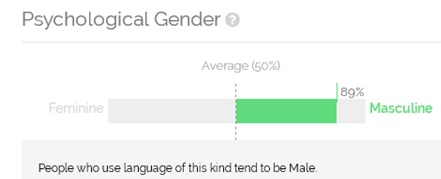
Text-based Personality Prediction: Looks like I am male in Spanish and female in German and English
Eine kleine Jeckigkeit zum Karneval: Das Psychometrics Centre der Universität Cambridge hat einen Online-Persönlichkeitstest entwickelt (vielen Dank an Note To Self für die Empfehlung!), der anhand von Textproben die Persönlichkeit des Verfassers ermittelt. Die psycholinguistische Analyse ergab in meinem Fall anhand meines Lebenslaufs in Deutsch, Englisch und Spanisch relativ einheitlich, dass ich männlich und Mitte bis…
-

Simultaneous interpreting with VR headset | Dolmetschen unter der Virtual-Reality-Brille | Interpretación simultanea con gafas VR
+++ for English see below +++ para español, aun más abajo +++ 2016 wurde mir zum Jahresausklang eine Dolmetscherfahrung der ganz besonderen Art zuteil: Dolmetschen mit Virtual-Reality-Brille. Sebastiano Gigliobianco hat im Rahmen seiner Masterarbeit am SDI München drei Remote-Interpreting-Szenarien in Fallstudien durchgetestet und ich durfte in den Räumen von PCS in Düsseldorf als Probandin dabei…
-
Christmas Speeches Medley * Weihnachtsansprachen-Medley * Potpourri internacional de discursos navideños …
… feat. Queen Elisabeth (1957), Konigin Beatrix (2006), el Rey Juan Carlos (1975), Bundespräsident Richard von Weizsäcker (1985), le Roi Philippe (2014), President Barack Obama (2015), Enrique Peña Nieto (2011), Bundespräsident Adolf Ogi (2000), President Xi Jinping (2016) Es ist schon alles gesagt, nur noch nicht von allen. * Everything has already been said, but…
-

Impressions from Translating and the Computer 38
The 38th ‘Translating and the Computer’ conference in London has just finished, and, as always, I take home a lot of inspiration. Here are my personal highlights: Sketch Engine, a language corpus management and query system, offers loads of useful functions for conference preparation, like web-based (actually Bing-based) corpus-building, term extraction (the extraction results come…
-
Hello from the other side – Chinese and Terminology Tools. A guest article by Felix Brender 王哲謙
As Mandarin Chinese interpreters, we understand that we are somewhat rare beings. After all, we work with a language which, despite being a UN language, is not one you’d encounter regularly. We wouldn’t expect colleagues working with other, more frequently used languages to know about the peculiarities of Mandarin. This applies not least to terminology…
-

Datensicherung für Mutter und Kinder | family-friendly data backup
+++ for English, see below +++ Was ich selbst in über 20 Jahren nicht fertiggebracht habe, schafft mein Kind schon vor dem Erreichen der digitalen Volljährigkeit (gleich Inhaberschaft eines eigenen Whatsapp-Kontos) – den totalen Datenverlust. Zwar in diesem Fall nur in Form aller kostbaren Fotos auf meinem ausrangierten Handy, aber immerhin. So langsam wird klar:…
-
Booth-friendly terminology management: Glossarmanager.de
Believe it or not, only a few weeks ago I came across just another booth-friendly terminology management program (or rather it was kindly brought to my attention by a student when I talked about the subject at Heidelberg University). It has been around since 2008 and completely escaped my attention. So I am all the…
-

Operation leerer Briefkasten
Während es zum Thema Reinhaltung des elektronischen Postfachs nicht nur Spamfilter, sondern bei seriösen Newslettern auch eine (vorgeschriebene) Abmeldefunktion gibt, ist es mit der Abwehr unnötiger Papierpost deutlich komplizierter. Komischerweise höre ich auch seltener jemanden über die Flut unnötiger Papiermengen im realen Briefkasten als über die Spam-Flut jammern, obwohl das Ausfiltern und Löschen von E-Mails…
-

Why not listen to football commentary in several languages? | Fußballspiele mehrsprachig verfolgen
+++ for English, see below +++ para español, aún más abajo +++ Ich weiß nicht, wie es Euch ergeht, aber wenn ich im Fernsehen ein Fußballspiel verfolge, frage ich mich mitunter, was jetzt wohl der Kommentator der anderen Mannschaft bzw. Nationalität dazu gerade sagt. Die Idee, (alternative) Fußballkommentare über das Internet zu streamen, hat sich…
-
The Future of Interpreting & Translating – Professional Precariat or Digital Elite?
Interpreters being paid by the minute (or hour) nowadays does not seem as inconceivable as it used to be. Technically speaking, small worktime and payment units have become easier to handle, thus more probable to be applied. The question arises if working and being paid on a micro or macro level, as the two extremes,…
-

Research topics in interpretation research | Ideen für Forschungsarbeiten in der Dolmetschwissenschaft
“Das wäre doch eine Superidee für eine Masterarbeit, oder gar ein Forschungsprojekt”, schießt es mir mitunter durch den Kopf. Aber man kann sich ja nicht um alles selbst kümmern … Und wenn ich dann Tage oder Wochen später nach einer Idee für eine Masterarbeit gefragt werde, fällt mir meist nichts ein. Deshalb werde ich fortan…
-
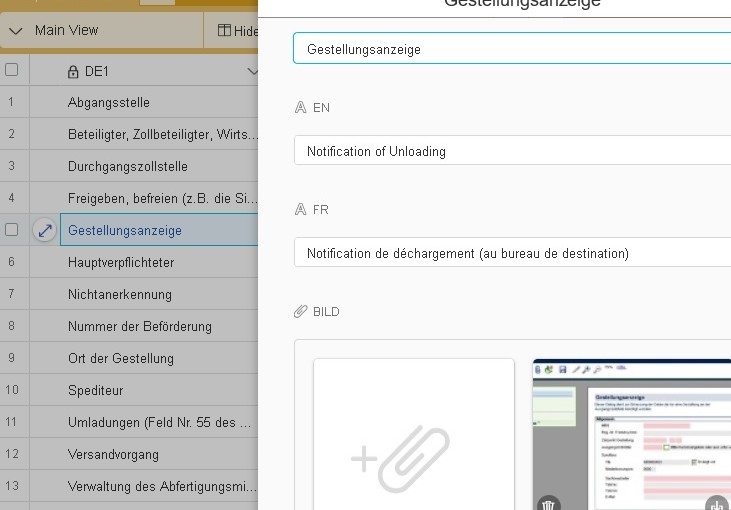
Airtable.com – a great replacement for Google Sheets | tolle Alternative zu Google Sheets
+++ for English see below +++ Mit der Terminologieverwaltung meiner Träume muss man alles können: Daten teilen, auf allen Geräten nutzen und online wie offline darauf zugreifen (wie mit Interpreters’ Help/Boothmate für Mac oder auch Google Sheets), möglichst unbedenklich Firmenterminologie und Hintergrundinfos des Kunden dort speichern (wie bei Interpreters’ Help), sortieren und filtern (wie in…
-

Dictation Software instead of Term Extraction? | Diktiersoftware als Termextraktion für Dolmetscher?
+++ for English see below +++ Als neulich mein Arzt bei unserem Beratungsgespräch munter seine Gedanken dem Computer diktierte, anstatt zu tippen, kam mir die Frage in den Sinn: “Warum mache ich das eigentlich nicht?” Es folgte eine kurze Fachsimpelei zum Thema Diktierprogramme, und kaum zu Hause, musste ich das natürlich auch gleich ausprobieren. Das…
-
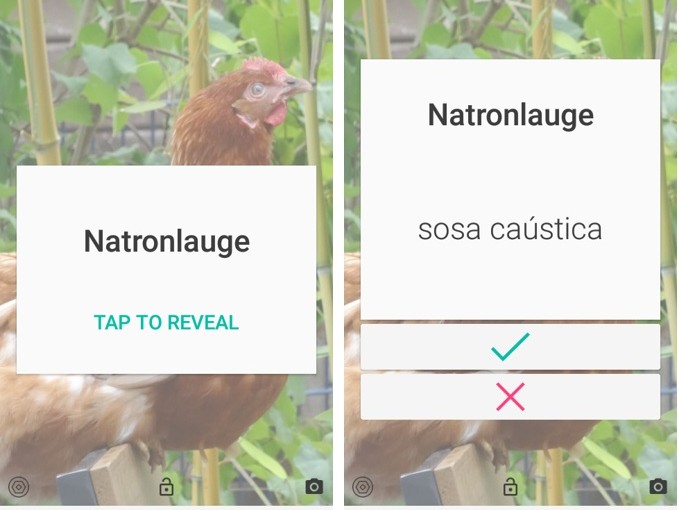
GetSEMPER.com – Charmant-penetranter Vokabeltrainer | Persistant, though charming: your personal vocab trainer
“Aktivierung von Schlüsselterminologie”, “Memor(is)ierung” oder “Vokabelpauken” – egal, wie man es nennt: Eine gewisse Basisausrüstung an Fachterminologie muss einfach ins Hirn. Hierzu kann man sich Listen ausdrucken, Karteikarten schreiben oder eine Reihe von Apps und Programmen nutzen (Anki, Phase 6, Langenscheidt und Pons wurden mir bei einer Spontanumfrage unter Kollegen genannt, auch die InterpretBank bietet…
-
Für die guten Vorsätze: Webinare 2016 | For your New Year’s resolutions: Webinars in 2016
+++ These webinars are all in German. If you’d like something similar in Spanish or English, just let me know! +++ WEBINAR KURZÜBERBLICK TERMINOLOGIE Für diejenigen, die sich in 90 Minuten einen Überblick über die Softwarelandschaft rund ums Terminologiemanagement für Konferenzdolmetscher verschaffen wollen, gibt es auch dieses Jahr wieder ein Webinar zusammen mit dem BDÜ…
-

In the booth or in the hen house – experts all around | Dolmetschkabine oder Hühnerstall – Expertentum, wohin man schaut | Entre expertos: ya sea en el gallinero o en la cabina de interpretación
+++ for English see below +++ para español, aun más abajo +++ Wie inspirierend der Bau eines Hühnerhäuschens sein kann, erschließt sich eventuell nicht auf den ersten Blick. Wer im Laufe der letzten Monate die Kabine mit mir teilen und meine Hühnerfotos bewundern musste, fragt sich aber vielleicht schon seit Längerem, wann die Hennen denn…
-

Zu Gast in Brüssel bei “Radio Alex”, auch bekannt als #LangFM
Diesen Monat war ich gemeinsam mit Leonie Wagener zu Gast in Brüssel an Alex Drechsel’s Podcast-Küchentisch. Sehr nett war’s – hier könnt Ihr reinhören: http://www.adrechsel.de/langfm/terminologie +++ Seminarankündigung +++ Wer beim Hören Appetit auf mehr Wissens- oder Terminologiemanagement bekommt und vom Rheinland nicht allzu weit entfernt ist (oder den Weg dorthin nicht scheut), könnte vielleicht Spaß…
-
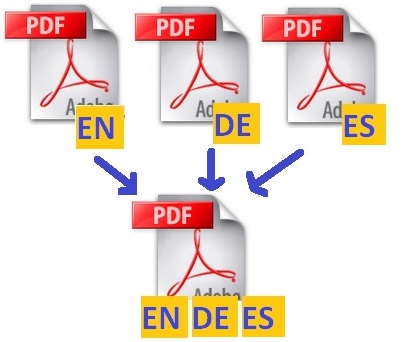
How to build one nice multilingual file from several PDFs | Aus zwei (PDFs) mach eins – übersichtliche mehrsprachige PDFs erstellen | Cómo crear un archivo PDF multilingüe
+++ for English see below +++ para español, aun más abajo +++ Wir kennen ihn alle: Den über hundert Seiten langen Geschäftsbericht, vollgepackt mit Grafiken, Tabellen und wertvollen Informationen, und das – Halleluja! – nicht nur im Original, sondern auch noch in 1a-Übersetzung(en) . Einen besseren Fundus für die Dolmetschvorbereitung kann man sich kaum vorstellen.…
-

Digital dementia and conference interpreters – article published in Multilingual July/August 2015
To read this article on effects of digitalisation on conference interpreters’ memory and learning habits, please follow the link to multilingual.com (English only). —————- About the author Anja Rütten is a freelance conference interpreter for German (A), Spanish (B), English (C) and French (C) based in Düsseldorf, Germany. She has specialised in knowledge management…
-
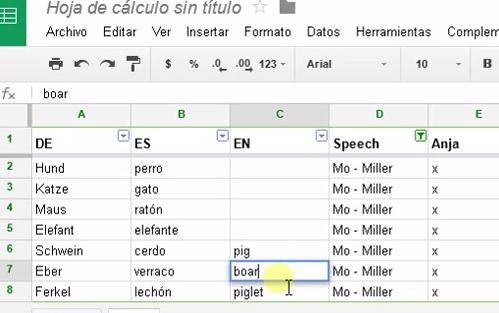
Shared glossaries in Google Docs – How to make them work for everyone | Team-Glossare in Google Docs – So wird’s was
+++ for English see below +++ Team-Glossare in Google Docs – So wird’s was Als unsere liebe Kollegin Leonie Wagener 2012 im Rahmen ihrer Masterarbeit eine Erhebung zur vorbereitende Terminologiearbeit unter Konferenzdolmetschern durchführte, gaben 93 % an, zumindest in der Kabine nie ihre Terminologie in Google Docs zu bearbeiten. Mittlerweile ist die gemeinsame Vorbereitung…
-

Booth-friendly terminology management: Intragloss – the missing link between texts and glossaries|die Brücke zwischen Text und Glossar
+++ for English see below +++ Wer schon immer genervt war von der ständigen Wechselei zwischen Redetexten/Präsentationsfolien einerseits und dem Glossar andererseits, der hat jetzt allen Grund zu jubilieren: Dan Kenig und Daniel Pohoryles aus Paris haben mit Intragloss eine Software entwickelt, in der man direkt aus dem Text Termini in sein Glossar befördern kann…
-
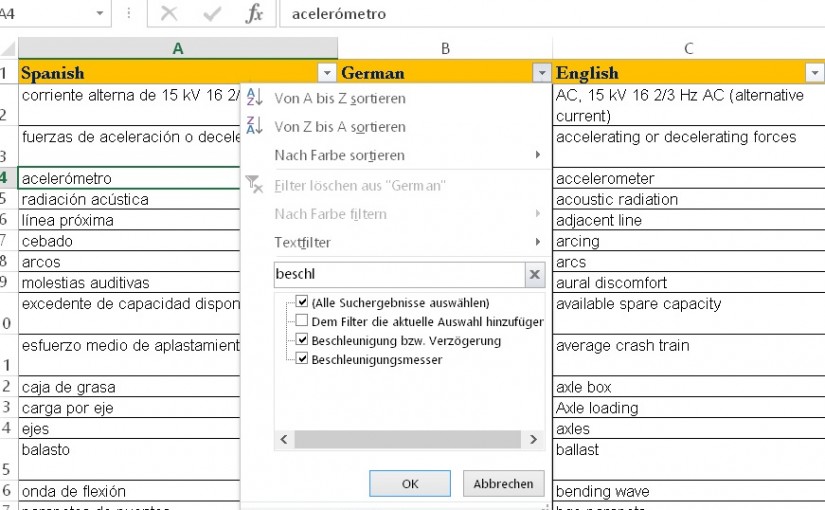
MS-Excel and MS-Access – are they any good for the booth? | Taugen MS-Excel und MS-Access für die Dolmetschkabine?
Es gibt zwar eine ganze Menge Programme, die genau auf die Bedürfnisse von Konferenzdolmetschern zugeschnitten sind (etwa die Schnellsuche in der Kabine oder Strukturen für die effiziente Einsatzvorbereitung), aber eine ganze Reihe von Kollegen setzt dennoch eher auf Feld-Wald-und-Wiesen-Lösungen aus der MS-Office-Kiste. Abgesehen von Word – hier enthalte ich mich jeden Kommentars hinsichtlich dessen Tauglichkeit…
-
Summary table of terminology tools for interpreters | Übersichtstabelle Terminologietools für Dolmetscher | cuadro sinóptico de programas de gestión de terminología para intérpretes
This is an overview of all the terminology management tools for conference interpreters that I am aware of. I will try to keep the information in the table up to date. If there is anything wrong, feel free to post a comment! Dies ist eine Übersicht über alle Terminologieverwaltungstools für Konferenzdolmetscher, die mir bekannt sind.…
-

Handschriftlich notieren oder tippen – was sagt die Forschung? | Handwriting vs. typing – what does research tell us?
+++ for English see below +++ Egal, in welchem Kreis von Dolmetschern man darüber redet, geschätzte 10 % schwören immer Stein und Bein, dass sie sich die Dinge besser merken können, wenn sie sie mit Stift und Papier festhalten. Sie pfeifen auch auf die Vorteile des papierlosen Büros, darauf, ihre Unterlagen durchsuchen und Glossare sortieren…
-
Webinar: Terminologieverwaltungstools für Konferenzdolmetscher am 28. April 2015
+++ This one comes in German only +++ Datum: 28.04.2015, 18:00 bis 19:30 Uhr Dieses Webinar richtet sich an praktizierende Konferenzdolmetscher, die sich gerne einen Überblick über die am Markt verfügbaren Terminologietools verschaffen möchten. Dabei spielt es keine Rolle, ob Sie viel oder wenig Erfahrung mit dem Einsatz von Computern in der Kabine haben. Die…
-
Booth-friendly terminology management – Flashterm.eu
+++ for English see below +++ Wer – womöglich auch fürs Übersetzen – eigentlich lieber eine “richtige” Terminologieverwaltung hätte, die obendrein aber noch kabinenfreundlich ist, der sollte einmal bei Flashterm von der Eisenrieth Dokumentations GmbH vorbeischauen. Flashterm basiert auf Filemaker und bietet die Klassiker der Eintragsmöglichkeiten wie Sachgebiete, Synonyme, Kontext usw. , aber auch das…
-
Mein Gehirn beim Simultandolmetschen| My brain interpreting simultaneously
+++ for English, see below +++ Für gewöhnlich fragen wir uns ja eher, was gerade um Himmels Willen im Kopf des Redners vorgeht, den wir gerade dolmetschen. Unsere Kollegin Eliza Kalderon jedoch stellt in ihrer Doktorarbeit die umgekehrte Frage: Was geht eigentlich in den Dolmetscherköpfen beim Simultandolmetschen vor? Zu diesem Zweck steckt sie Probanden in…
-

Kabinentauglicher Adventskranz | DIY Advent Wreath | Corona de adviento para armar
Mein Blog wird in diesen Tagen 1 Jahr alt – Danke fürs Lesen, Kommentieren, Teilen und Ermutigen und Euch allen eine schöne Vorweihnachtszeit! Wenn Ihr noch einen kabinentauglichen Adventskranz benötigt, bitteschön – einfach ausdrucken und zusammenbauen: DIY Adventskranz My blog turns one year these days – thanks for reading, commenting, sharing and all your encouragement…
-

Not-To-Do Lists and Not-To-Learn Words
+++ For English see below +++ To-Do-Listen sind eine feine Sache: Einmal aufgeschrieben, kann man lästige Aufgaben zumindest zeitweilig des Gedächtnisses verweisen, und überhaupt ist man viel organisierter und effizienter. Ich zumindest gieße seit Ewigkeiten alles, was nicht bei drei auf den Bäumen ist, in eine Excel-Tabelle – seien es nun Geld, Arbeit, Adressbuch oder…
-
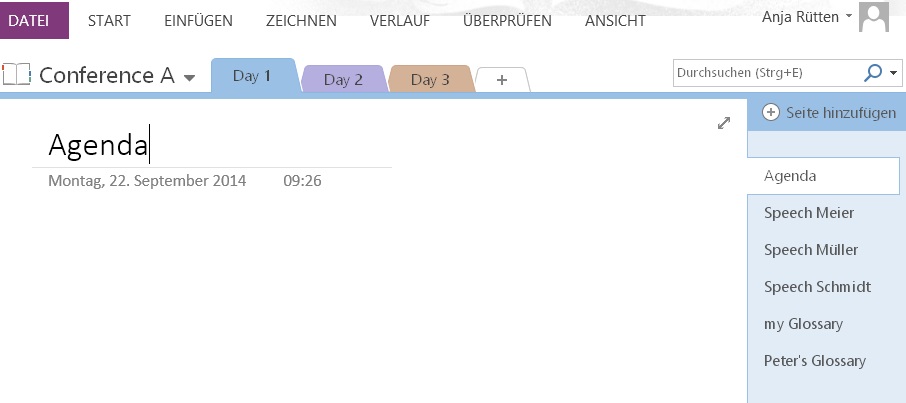
Organise your meeting documents with MS-OneNote – Sitzungsunterlagen perfekt im Zugriff mit Onenote
+++ for English see below +++ Warum scheuen viele Dolmetscher eigentlich davor zurück, völlig papierfrei in die Kabine zu gehen, und wechseln lieber zwischen einem Stapel ausgedruckter Dokumente auf der einen Seite und einem Computer als reine Vokabelsuchmaschine auf der anderen Seite hin und her? Ich vermute, der Grund ist dieser: Man kann einfach nie…
-
Improved Reading für Dolmetscher – neue Termine für August und September in Frankfurt, Karlsruhe, Berlin, Hamburg
Improved Reading bietet neue Crashkurs-Termine speziell für Dolmetscher. Preis: 169,- € zzgl. MwSt. (beinhaltet alle Kursunterlagen, die Nachbetreuung, Softgetränke und Kaffee während des Trainings) Max. 15 Teilnehmer, Anmeldung möglichst bis 4 Wochen vorher Frankfurt – Sa, 30.08.14 09:30 – 17:30 Karlsruhe – Mo, 01.09.14 09:30 – 17:30 Berlin – Fr, 19.09.14 09:30 – 17:30 Hamburg…
-

Verträge auf dem Smartphone oder Tablet unterschreiben +++ Signing contracts on your smartphone or tablet
+++ For English see below +++ Man kennt es ja: Gerade liegt man unter Palmen, da schneit per Mail der Vertrag für den nächsten Auftrag hinein und will sofort unterschrieben zurückgeschickt werden. Und nun? Zur Rezeption laufen, Vertrag ausdrucken lassen (supervertraulich) und unterschrieben zurückfaxen? Natürlich nicht. Denn zu meiner übergroßen Freude habe ich in meinem…
-

Do interpreters suffer from decision fatigue? – Entscheidungsmüdigkeit beim Dolmetschen?
+++ for English see below +++ Entscheidungen sind anstrengend. Chicken or Pasta, Sekt oder Selters, Windows oder Mac, vom Blatt dolmetschen oder frei – den ganzen Tag müssen wir uns entscheiden, und je mehr Entscheidungen sich aneinander reihen, desto entscheidungsmüder werden wir, desto weniger gründlich wägen wir die Möglichkeiten also ab oder bleiben im Zweifel…
-

Quick multi-site terminology search | Terminologiesuche in verschiedenen Online-Quellen
For English see below Mal eben bei linguee.com, leo.org, IATE und anderen Nachschlageseiten prüfen, was ein “gillnet” ist und wie man dazu auf Deutsch oder Spanisch sagt, ohne etlichen Webseiten aufrufen und das Wort jedes Mal neu eintippen zu müssen – davon träume ich schon lange. Seit vielen Jahren probiere ich immer wieder Tools dafür…