Tag: interpretacion simultanea
-
How to build one nice multilingual file from several PDFs | Aus zwei (PDFs) mach eins – übersichtliche mehrsprachige PDFs erstellen | Cómo crear un archivo PDF multilingüe
+++ for English see below +++ para español, aun más abajo +++ Wir kennen ihn alle: Den über hundert Seiten langen Geschäftsbericht, vollgepackt mit Grafiken, Tabellen und wertvollen Informationen, und das – Halleluja! – nicht nur im Original, sondern auch noch in 1a-Übersetzung(en) . Einen besseren Fundus für die Dolmetschvorbereitung kann man sich kaum vorstellen.…
-
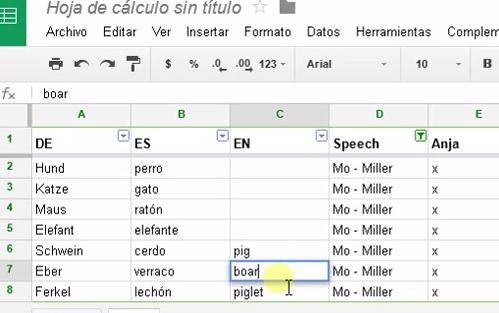
Shared glossaries in Google Docs – How to make them work for everyone | Team-Glossare in Google Docs – So wird’s was
+++ for English see below +++ Team-Glossare in Google Docs – So wird’s was Als unsere liebe Kollegin Leonie Wagener 2012 im Rahmen ihrer Masterarbeit eine Erhebung zur vorbereitende Terminologiearbeit unter Konferenzdolmetschern durchführte, gaben 93 % an, zumindest in der Kabine nie ihre Terminologie in Google Docs zu bearbeiten. Mittlerweile ist die gemeinsame Vorbereitung…