Year: 2018
-

What do conference interpreters’ booth notes tell us about their information management?
First of all, a big thank you to all of you who followed my call and provided copies of their booth notes for my little study – I finally managed to collect booth notes from 25 colleagues! Now, what was this study all about? The purpose was to see what interpreters write down intuitively on…
-
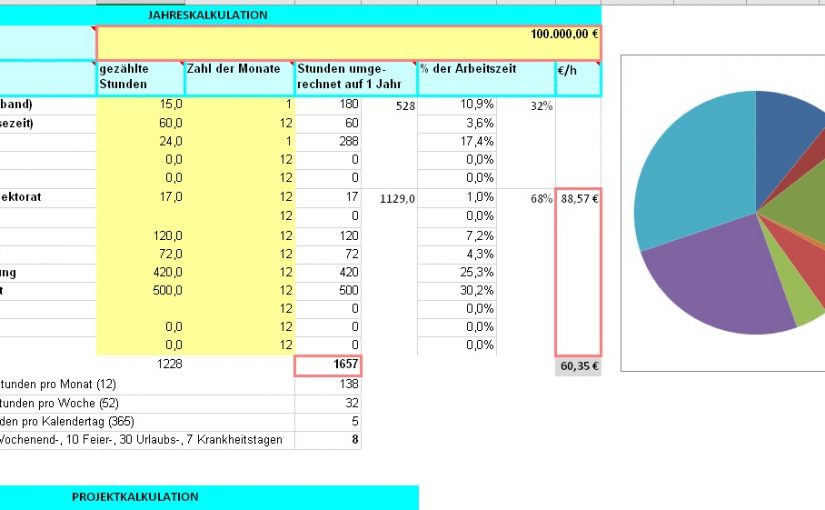
Honorarkalkulator für Dolmetscher – Excel-Datei und Video Tutorials aus #aiicDfD2018
“Grundhonorare, Projekthonorare, Vorbereitungshonorare – nicht immer funktionieren Tagessätze” – laut Inés de Chavarría (der ein megagroßes Dankeschön für die Orga gebührt!) eine zentrale Erkenntnis aus den Diskussionen des AIIC-Workshops Dolmetscher für Dolmetscher 2018 in Stuttgart. In diesem Sinne nun also ran ans Kalkulieren! Hier zum Ansehen in Google Sheets oder zum Herunterladen im Excel-Format der…
-

Nicht für Geld – kleines Einmaleins für Dolmetscher
Zur Einstimmung auf den bevorstehenden Dolmetscher-für-Dolmetscher-Workshop, wo es unter anderem um betriebswirtschaftliche Themen gehen wird, möchte ich heute ein paar Gedanken zu einem meiner Lieblingsthemen, dem lieben Geld, mit Euch teilen. Denn den schönsten Beruf der Welt macht man zwar nicht nur des Geldes wegen, aber ohne wäre irgendwie auch schlecht. Und wenn Dolmetscher auch…
-
Green Season’s Greetings | Grüne Weihnachtsgrüße | Saludos navideños verdes
-
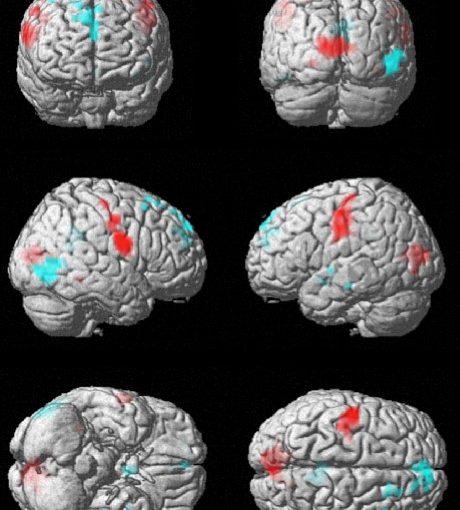
Neurophysiologie des Simultandolmetschens | Neurophysiology of simultaneous interpreting – by Eliza Kalderon
+++ for English, scroll down +++ Etwa eineinhalb Jahre nach Beenden der Promotion freue ich mich über die Möglichkeit, im Blog meiner Kollegin, die das Projekt “Neurophysiologie des Simultandolmetschens: eine fMRI-Studie mit Konferenzdolmetschern” von Anfang an voller Begeisterung und Engagement unterstützte, eines der spannendsten Ergebnisse vorstellen zu dürfen. Die drei nachfolgenden Abbildungen stellen sogenannte Render-Bilder…
-
Macht mehr Monotasking?
Ich kann es ja eigentlich nicht mehr hören: “Wir fummeln viel zu oft an unseren Handys herum! Wir sind immer abgelenkt. Wir müssen mal wieder ein Buch umarmen! Und in ein Geschäft gehen!” Hallo? WIR sind erwachsen und lieben Computer und Handys auch, weil sie einen Ausknopf haben. Den haben nämlich weder Aktenberge noch vollgestopfte…
-
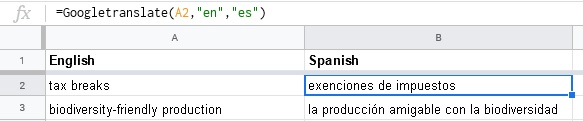
How to Build Your Self-Translating Glossary in Google Sheets
I am certainly not saying that Google can create your glossaries for you when preparing for a technical conference on African wildlife or nanotubes. But if you know your languages well enough to tell a bad translation from a good one, it may still be a time-saver. Especially for those words you don’t use every…
-

Word Clouds – much nicer than Word Lists
I have been wondering for quite some time if word lists are the best thing I can come up with as a visual support in the booth. They are not exactly appealing to the eye, after all … So I started to play around with word cloud generators a bit to see if they are…
-
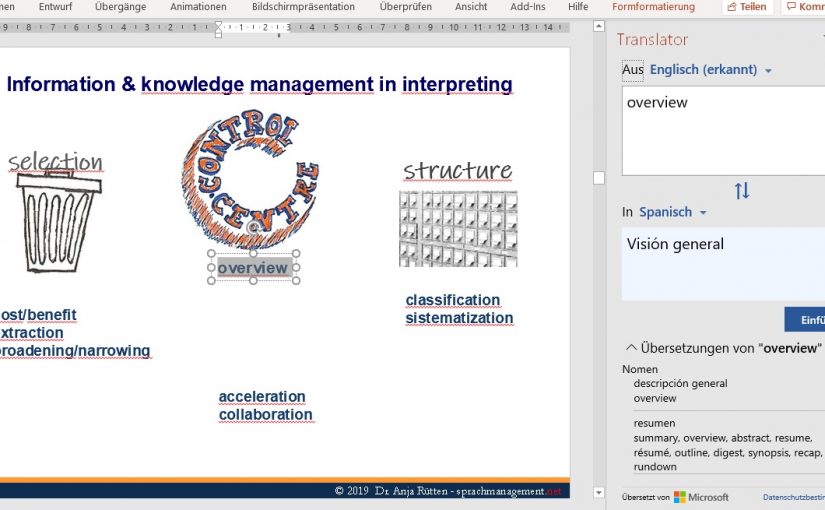
Microsoft Office Translator – Can it be of any help in the booth?
When it comes to Computer-Aided Interpreting (CAI), a question widely discussed in the interpreting community is whether information being provided automatically by a computer in the booth could be helpful for simultaneous interpreters or if would rather be a distraction. Or to put it differently: Would the cognitive load of simultaneous interpreting be increased by…
-

How to measure the efficiency of your conference preparation
Half of the time we dedicate to a specific interpreting assignment is often spent on preparation. But while many a thought is given to the actual interpreting performance and the different ways to evaluate it, I hardly ever hear anyone discuss their (or others’) preparation performance. However, if we want to be good information and…
-

About Term Extraction, Guesswork and Backronyms – Impressions from JIAMCATT 2018 in Geneva
JIAMCATT is the International Annual Meeting on Computer-Assisted Translation and Terminology, a IAMLAP taskforce where most international organizations, various national institutions and academic bodies exchange information and experience in the field of terminology and translation. For this year’s JIAMCATT edition in Geneva, I had the honour of running a workshop on Tools for Interpreters –…
-

You love keyboard shortcuts? Meet GT4T!
GT4T – key shortcuts made for translators and interpreters (for German and Spanish, scroll down) If you asked me, everyone should learn key shortcuts at school together with their ABC. Once memorised, they are so convenient to use … unlike buttons on the screen, you just feeeeel them without having to look. It seems like…
-

Speechpool, InterpretimeBank & InterpretersHelp – the Perfect Trio for Deliberate Practice in Conference Interpreting
After testing the practice module of InterpretersHelp last month, the whole practice thing got me hooked. Whilst InterpretersHelp gives us the technical means to record our interpretation together with the original and receive feedback from peers, there are two more platforms out there which cover further aspects of the practice workflow: InterpretimeBank and Speechpool. To…
-

Cleopatra: an App for Automating Symbols for Consecutive Interpreting Note-Taking – Guest Article by Lourdes de la Torre Salceda
+++ For Spanish scroll down +++ The perfect symbol has just come to mind! I’ve been racking my brain for ages and I got it, finally! I’ve been inspired! But where should I write it down, now that I’m sunbathing on the beach! Has something similar ever occurred to you? As a millennial the first…
-
New Term Extraction Features in InterpretBank and InterpretersHelp – Thumbs up!
Extracting terminology from preparatory texts into a term database seems to be the hot topic of the moment, judging by what the two most active and innovative CAI (computer-assisted interpreting) tools, InterpretBank and InterpretersHelp, are working on at the moment. So while I am still waiting to become a Windows beta tester of Intragloss, the…
-
InterpretersHelp’s new Practice Module – Great Peer-Reviewing Tool for Students and Grownup Interpreters alike
I have been wondering for quite a while now why peer feedback plays such a small role in the professional lives of conference interpreters. Whatwith AIIC relying on peer review as its only admission criterion, why not follow the logic and have some kind of a routine in place to reflect upon our performance every…
-
Flashterm revisited. A guest article by Anne Berres
+++ für deutsche Fassung bitte runterscrollen +++ One of everything, please! Have you ever wished there was a terminology management system (TMS) that would provide all the functions you are looking for and prepare for the conference largely automatically? Wouldn’t that be splendid? You’d just have to type in the event’s title and the…